
Stability AIのStable Diffusion

Stability AIが開発したStable Diffusionは、テキストから画像を生成する人工知能モデルとして注目を集めています。このAIは高品質な画像を生成できる一方で、いくつかの懸念点も指摘されています。
Stable Diffusionの主な特徴:
- オープンソースで無料で利用可能
- テキストプロンプトから多様な画像を生成
- ローカル環境でも動作可能
- 高速な画像生成が可能
インストール手順:
- Pythonとgitをインストール
- リポジトリをクローン
- 必要なライブラリをインストール
- モデルをダウンロード
- WebUIを起動
しかし、Stable Diffusionには以下のようなリスクがあります:
- 著作権侵害の可能性
学習データに著作権のある画像が含まれている可能性があり、生成画像が著作権を侵害する恐れがあります。 - 不適切なコンテンツ生成
ポルノグラフィーや暴力的な画像など、倫理的に問題のあるコンテンツが生成される可能性があります。 - ディープフェイク作成のリスク
実在する人物の画像を悪用して偽の画像を作成できる危険性があります。 - バイアスと差別
学習データに含まれるバイアスにより、特定の人種や性別に偏った画像が生成される可能性があります。 - プライバシー侵害
個人情報を含む画像が生成される可能性があります。
これらのリスクを考慮し、Stable Diffusionを利用する際は細心の注意を払う必要があります。適切な使用ガイドラインを設け、生成された画像の確認を徹底することが重要です。また、著作権や肖像権に配慮し、法的・倫理的な問題を回避するよう心がけましょう。
Stable Diffusionは強力なツールですが、責任ある使用が求められます。技術の進歩と共に、これらの課題に対する解決策も進化していくことが期待されます。
留意点:Stable Diffusionの画像生成
Stable Diffusionとは?
Stable Diffusionは、テキストや画像プロンプトを入力として、リアルな画像を生成するAIモデルです。2022年にStability AIによって初めてリリースされ、オープンソースとして提供されています。これにより、誰でも無料で利用でき、独自の画像生成AIを作成することが可能です[2][3]。
データ要件
Stable Diffusionを利用するためには、以下のデータが必要です:
- テキストプロンプト:生成したい画像の内容を記述します。例えば、「サングラスをかけた猫」など。
- 画像プロンプト(オプション):既存の画像を基に新しい画像を生成する場合に使用します。
また、モデルのトレーニングやファインチューニングを行う場合には、追加の学習データが必要です。これにより、特定のスタイルやテーマに合わせた画像生成が可能になります。
Stable Diffusionモデル
Stable Diffusionは、ディープラーニングに基づく拡散モデル(Diffusion Model)を採用しています。このモデルは、潜在空間を利用して効率的に学習し、ノイズを除去しながら画像を生成します。具体的には、以下のプロセスを経て画像が生成されます:
- 拡散プロセス:入力画像を低次元の潜在表現に変換し、ノイズを付加します。
- 逆拡散プロセス:ノイズを徐々に除去し、元の画像に近づけます。
このプロセスにより、高品質な画像が生成されます。
ノイズ除去
Stable Diffusionでは、画像生成の過程でノイズを除去することが重要です。ノイズ除去の強度(Denoising Strength)は0から1まで設定可能で、値が大きいほどノイズが除去されますが、画像がぼやける可能性があります。逆に、値が小さいとノイズが残りますが、画像の鮮明度が向上します。
ノイズ除去の設定例
| Denoising Strength | 特徴 |
|---|---|
| 0.0 – 0.5 | ノイズが残るが、画像が鮮明 |
| 0.6 – 0.8 | バランスが良い |
| 0.9 – 1.0 | ノイズが完全に除去されるが、画像がぼやける |
推奨スペック
Stable Diffusionを効率的に利用するためには、以下のPCスペックが推奨されます:
- OS:Windows(64bit)
- CPU:最新モデルのCore i5~Core i7、Ryzen 5~7
- GPU:RTX 30シリーズやRTX 40シリーズのVRAMが12GB以上
- メモリ:16GB~32GB
- ストレージ:512GB以上
これらのスペックを満たすことで、高品質な画像生成が可能となります。
Stable Diffusionは、テキストや画像プロンプトを基に高品質な画像を生成するAIモデルです。オープンソースで提供されており、誰でも無料で利用可能です。ノイズ除去の設定や推奨スペックに注意しながら利用することで、効率的に画像を生成することができます。
Stable Diffusionによる動画生成の可能性
Stable Diffusionを用いた動画生成は、AI技術の進化により、非常に高品質でリアルな動画を生成することが可能となっています。以下に、Stable Diffusionによる動画生成の特徴、必要なスペック、およびセキュリティについて詳しく説明します。

Stable Diffusionによる動画生成の特徴
1. 高品質な動画生成
Stable Diffusionは、テキストや画像から高解像度の動画を生成することができます。例えば、「山にいる氷の龍」といった具体的なプロンプトを入力するだけで、そのシーンをリアルに再現した動画を生成することが可能です[10]。
2. カスタマイズ可能なフレームレート
ユーザーは3fpsから30fpsまでのフレームレートを選択でき、滑らかな動きの動画やスローモーション効果を持つ動画など、さまざまなスタイルの動画を作成することができます[10]。
3. 多様な応用分野
Stable Diffusionは映画制作、医療分野、自動車産業など、多岐にわたる分野で活用されています。特に、広告やマーケティング素材の生成においても効果的です[2][4]。
スペックを必要とするStable Diffusionの動画生成
Stable Diffusionを用いた動画生成には高いスペックのPCが必要です。以下に推奨スペックを示します。
| 推奨スペック | 詳細 |
|---|---|
| 使用するPC | デスクトップ型 |
| OS | Windows(64bit) |
| CPU | 最新モデルのCore i5~Core i7、Ryzen 5~7 |
| GPU | RTX 30シリーズやRTX 40シリーズのVRAMが12GB以上 |
| メモリ | 16GB~32GB |
| ストレージ | 512GB以上 |
特に、GPUの性能が重要で、RTXシリーズのグラフィックボードが推奨されます。VRAM容量は12GB以上が望ましいですが、16GB以上あればより満足のいく結果が得られる可能性が高いです[7][8][11]。
動画生成の際のStable Diffusionのセキュリティ
1. 著作権と肖像権の懸念
Stable Diffusionを使用する際には、生成されたコンテンツが著作権や肖像権を侵害しないように注意が必要です。特に、プロンプトに画像を使用する場合には、生成された動画が他人の権利を侵害しないようにすることが重要です。
2. 商用利用の可否
Stable Diffusionは商用利用も可能ですが、利用規約に従う必要があります。生成されたコンテンツの権利はユーザーにありますが、適用される法律や規制に違反しないように使用することが求められます。
3. セキュリティ対策
Stable Diffusionはオンプレミスでも運用可能で、機密情報の安全性を保ちながら使用できます。ただし、セキュリティ対策として、データの管理やアクセス制御を適切に行うことが重要です。
Stable Diffusionを用いた動画生成は、非常に高品質でリアルな動画を生成する能力を持ち、多様な応用分野で活用されています。動画生成には高いスペックのPCが必要であり、特にGPUの性能が重要です。また、セキュリティ面では著作権や肖像権の侵害に注意し、適切なセキュリティ対策を講じることが求められます。
商用向けStable Diffusionのテキスト生成機能
Stable Diffusionは、画像生成AIとして広く知られていますが、最近ではテキスト生成機能も注目を集めています。特に商用利用においては、効率的なコンテンツ作成を可能にする強力なツールとなっています。

テキスト生成の新機能
Stable Diffusion 3の登場により、テキスト生成機能が大幅に向上しました。最も注目すべき点は、画像内に正確な文字を出力できるようになったことです。これにより、バナーやクリエイティブ画像の作成が格段に簡単になりました。
活用方法
Stable Diffusionを用いたテキスト生成には、主に2つの方法があります:
- Webアプリケーション上の環境を利用
- ローカル環境にインストールして使用
初心者の場合は、Hugging FaceやDream Studioなどのウェブサービスを利用するのが簡単です。より高度な利用を目指す場合は、GitHubで公開されているコードを使ってローカル環境で実行することも可能です。
タイトルや見出し作成への貢献
Stable Diffusionは、魅力的なタイトルや見出しの作成に大きく貢献しています。以下のような利点があります:
- キーワードに基づいた創造的な表現の生成
- 多様なバリエーションの提案
- 視覚的要素と文字の統合
これらの機能により、コンテンツ作成者は短時間で印象的なタイトルや見出しを作成できるようになりました。
商用利用における注意点
Stable Diffusionを商用利用する際は、以下の点に注意が必要です:
- ライセンス条項の確認
- 生成されたコンテンツの品質チェック
- 著作権や商標に関する法的問題の回避
適切に利用すれば、Stable Diffusionは商用コンテンツ制作の強力な味方となるでしょう。
テキスト生成AIの進化は目覚ましく、Stable Diffusionはその最前線にいます。今後も機能の拡張や精度の向上が期待され、ビジネスにおけるコンテンツ制作の在り方を大きく変えていく可能性があります。
Stable Diffusionの利用方法と安全性
Stable Diffusionは、テキストプロンプトから高品質な画像を生成できる強力なAIツールです。その利用方法と安全性について、以下にまとめます。
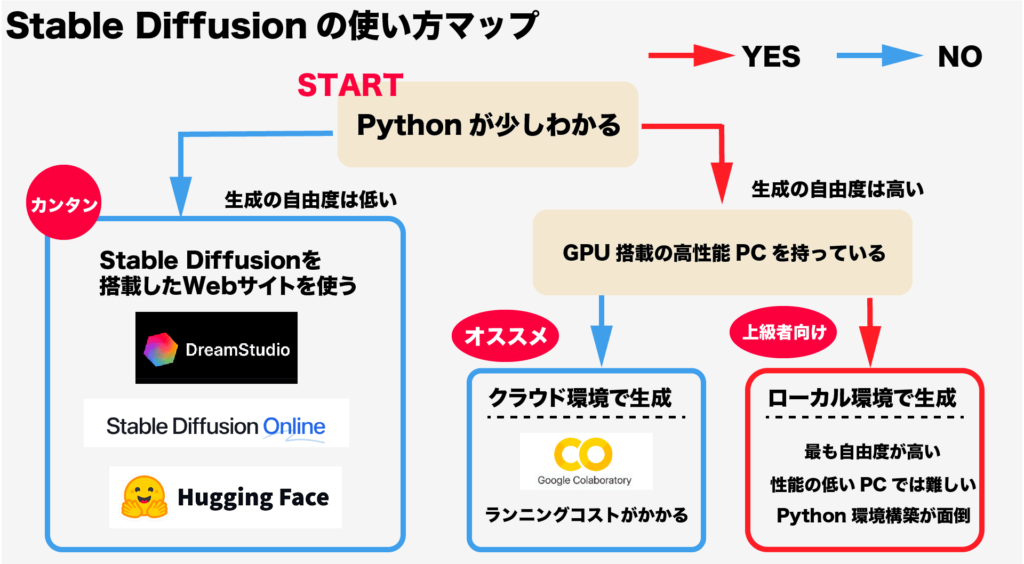
利用方法
Stable Diffusionを使用するには主に2つの方法があります:
- Webベースのインターフェース
- Dream Studio、Hugging Face、Midjourney等のオンラインプラットフォーム
- ブラウザから簡単にアクセス可能
- 低スペックPCでも利用可能
- ローカル環境へのインストール
- 自身のPCにソフトウェアをインストール
- より高度なカスタマイズが可能
- 高スペックPCが必要
安全な画像生成手順
- 適切なプロンプト作成
- 重要なキーワードを先に配置
- カンマと半角スペースで単語を区切る
- ネガティブプロンプトを活用し、不要な要素を除外
- 生成設定の調整
- 画像サイズ、生成ステップ数等のパラメータを最適化
- サンプラーの選択
- 結果の確認と修正
- 生成された画像を慎重に確認
- 必要に応じてプロンプトを調整し再生成
商用利用におけるセキュリティ機能
Stable Diffusionは商用利用が可能ですが、以下の点に注意が必要です:
- ライセンス確認: CreativeML Open RAIL-Mライセンスを確認
- コンテンツフィルタリング: 不適切なコンテンツの自動フィルタリング
- プライバシー保護: 個人情報を含む画像生成の制限
セキュリティ向上のための活用
- データ匿名化
- センシティブな情報を含む画像の代替として使用
- セキュリティトレーニング
- フィッシング対策等のセキュリティ教育用画像の作成
- シナリオプランニング
- セキュリティインシデントのビジュアル化
以下は、Stable Diffusionの利用方法と安全性に関する主要ポイントをまとめた表です:
| 項目 | 詳細 |
|---|---|
| 利用方法 | Webベース、ローカルインストール |
| 主要プラットフォーム | Dream Studio, Hugging Face, Midjourney |
| プロンプト作成のコツ | 重要キーワードを先に、カンマ区切り、ネガティブプロンプト活用 |
| 商用利用の注意点 | ライセンス確認、コンテンツフィルタリング、プライバシー保護 |
| セキュリティ活用例 | データ匿名化、セキュリティトレーニング、シナリオプランニング |
Stable Diffusionは強力なツールですが、適切な使用と安全性への配慮が重要です。商用利用の際は特に、法的・倫理的な観点からの慎重な判断が求められます。
Stable Diffusionの拡散モデルと向き合う
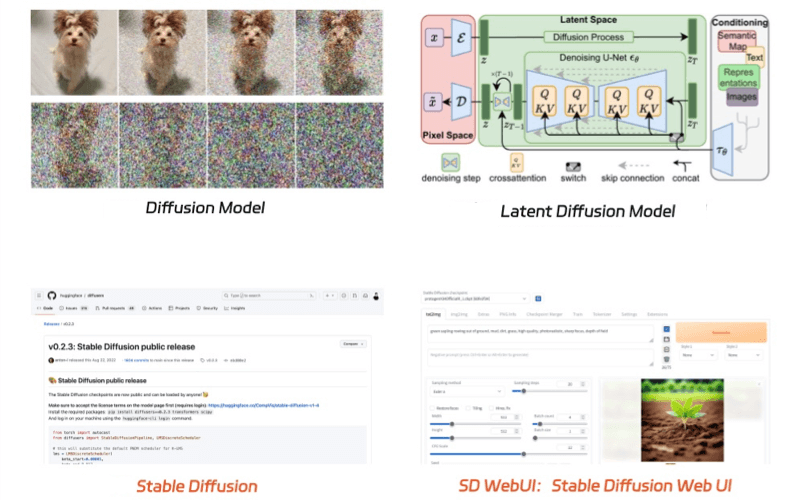
基本理解
Stable Diffusionは、画像生成AIの一種であり、特に高解像度かつ高品質な画像を生成するために設計された拡散モデル(Diffusion Model)です。このモデルは、データ(例えば画像)に段階的にノイズを加え、その後逆プロセスでノイズを取り除くことで元のデータを再構成する生成モデルの一種です[2][4]。
拡散モデルの基本概念
- 拡散プロセス(Diffusion Process): データポイントが徐々にランダムなノイズに変換されるプロセスです。マルコフ連鎖を使用して段階的に進行します。
- 逆拡散プロセス(Reverse Diffusion Process): ノイズから元のデータを徐々に再構築します。生成モデルはこの逆プロセスを学習し、新しいデータを生成します。
実利用における役割
Stable Diffusionは、特に以下のような用途で実利用されています:
- テキストから画像生成: ユーザーが入力したテキストを基に画像を生成します。これは、広告やデザイン、エンターテインメントなど多岐にわたる分野で利用されています。
- 画像の拡張: 既存の画像を基に新しいバリエーションを生成することができます。これにより、データセットの拡張やクリエイティブなコンテンツの生成が容易になります。
学習と生成のプロセス
Stable Diffusionの学習プロセスでは、以下のステップが含まれます:
- 入力データのエンコード: 画像はVAE(Variational Auto-Encoder)のエンコーダによって潜在空間に変換され、テキストはText Encoderによって埋め込まれます。
- 拡散過程: 画像の潜在表現に微小のガウシアンノイズを繰り返し加算し、最終的にはノイズに変換します。
- 逆拡散過程: ノイズから少しずつガウシアンノイズを除去し、元の画像を復元します。この過程はU-Netによって学習されます。
リリースの可能性
Stable Diffusionの拡散モデルは、その高い汎用性と性能から、以下のような多くの分野でのリリースが期待されています:
- クリエイティブ産業: 映画、ゲーム、広告などでのビジュアルコンテンツの生成。
- 医療分野: 医療画像の生成や解析。
- 教育分野: 教材やシミュレーションのための画像生成。
- エンタープライズ用途: 製品デザイン、プロトタイピング、マーケティング資料の作成。
図解
以下は、Stable Diffusionの基本的なアーキテクチャを示した図です:
+------------------+ +------------------+ +------------------+
| VAE Encoder | | U-Net | | VAE Decoder |
| (Image to | --> | (Noise Removal) | --> | (Latent to |
| Latent Space) | | | | Image Space) |
+------------------+ +------------------+ +------------------+この図は、画像がVAEエンコーダによって潜在空間に変換され、U-Netによってノイズが除去され、最終的にVAEデコーダによって元の画像が再構成されるプロセスを示しています。
Stable Diffusionの拡散モデルは、画像生成の新たな可能性を切り開く技術として、今後も多くの分野での活用が期待されます。
Stable Diffusionのモデルに関する話題

Stable Diffusionモデルに関する最新の動向や話題について、いくつかの興味深い展開がありました。
まず、モデルのランキングに関しては、Civitaiというプラットフォームが注目を集めています。Civitaiは、Stable Diffusionのモデルファイルを共有するサイトで、無料でダウンロードできるモデルのリアルタイムランキングを提供しています。このランキングは常に更新されており、最新の人気モデルや傾向を把握するのに役立ちます。
Stable Diffusionの基本的な仕組みについては、入力されたテキストをもとに画像を生成する訓練済みAIモデル(Diffusion Model)を搭載しています。ユーザーは作成したい画像のイメージを英単語で入力することで、様々な画像を生成できます。この技術は、アマゾンのジャングルや高層ビルが建ち並ぶ都会など、多様なシーンの画像生成に活用されています。
最近の話題としては、Stability AIが最新モデル「Stable Diffusion 3 Medium」をリリースしましたが、期待されていた品質に達しなかったことを認めています。これを受けて、同社は改善版のリリースを予定しており、ユーザーコミュニティからのフィードバックを反映させる方針を示しています。
また、Stability AIは商用ライセンスの修正も行いました。新しいライセンスでは、非商用利用は引き続き無料で、年間収益が100万米ドルを超えない個人クリエイターや小規模事業者の商用利用も無料となっています。これにより、より多くのユーザーがStable Diffusionモデルを活用できるようになりました。
Stable Diffusionの利用方法としては、主にWebアプリケーション上の環境とローカル環境での利用の2通りがあります。Webアプリケーションを利用すれば、プログラミングの知識がなくても簡単に画像生成AIを体験できるため、初心者にも親しみやすい選択肢となっています。
これらの動向は、Stable Diffusionが画像生成AI技術の分野で重要な位置を占めていることを示しています。モデルの継続的な改善や利用しやすいプラットフォームの提供により、今後もクリエイティブな表現の可能性を広げていくことが期待されます。





