
Stable Diffusion AIとは?紹介

Stable Diffusionは、2022年に公開されたディープラーニングを用いたテキストから画像を生成するAIモデルです。このモデルは、ミュンヘン大学のCompVisグループが開発し、EleutherAIとLAIONの支援を受けてStability AI、CompVis LMU、Runwayの三者が共同で公開しました。Stable Diffusionは、潜在拡散モデル(latent diffusion model)を使用し、深層生成ニューラルネットワークの一種です。
Stable Diffusion AIの機能
Stable Diffusionの主な機能は以下の通りです:
- テキストから画像生成:ユーザーが入力したテキストプロンプトに基づいて画像を生成します。例えば、「アマゾンのジャングル」や「高層ビルが建ち並ぶ都会」などの具体的なイメージを英語で入力することで、対応する画像を生成します。
- 高解像度画像生成:細部まで精密な高解像度画像を生成する能力があります。これにより、プロフェッショナルなビジュアルコンテンツの作成が可能です。
- 既存画像の編集と変換:既存の画像を編集または変換する能力も持ち、既にあるビジュアルを基に新たなクリエイティブな作品を生み出すことができます。
- 多様なスタイルの画像生成:リアルな写真風からアニメ風まで、様々なスタイルの画像を生成できます。
- インペインティングとアウトペインティング:画像の一部を修正したり、画像の範囲を拡張して新たな部分を生成することができます。
Stable Diffusion AIの利用方法
Stable Diffusionの利用方法は主に以下の3通りです:
- オンラインサービスの利用:
- Stable Diffusion OnlineなどのWebアプリケーションを利用することで、環境構築不要で簡単に画像生成が可能です[9]。
- Hugging FaceやDream Studioなどのプラットフォームでも利用できます。
- クラウドストレージの利用:
- Google Colaboratoryなどのクラウド環境を利用することで、スペックの低いPCやスマホでも利用可能です。ただし、有料プランへの加入が必要な場合があります。
- ローカル環境での利用:
- 自分のPCにStable Diffusionをインストールして利用する方法です。無料で無制限に利用でき、カスタマイズも自由に行えますが、高スペックPCが必要です。
Stable Diffusion AIのダウンロード方法
Stable Diffusionをローカル環境にインストールする手順は以下の通りです:
- Pythonのインストール:
- Pythonの公式サイトから最新バージョンをダウンロードしてインストールします。
- Gitのインストール:
- Gitの公式サイトからGitをダウンロードしてインストールします。
- Stable Diffusion Web UIのダウンロード:
- GitHubから「AUTOMATIC1111 Stable Diffusion WebUI」リポジトリをクローンします。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cd stable-diffusion-webui- 依存関係のインストール:
- 必要なPythonパッケージをインストールします。
pip install -r requirements.txt- モデルのダウンロード:
- Stable Diffusionのモデルファイルをダウンロードし、適切なフォルダに配置します。
- Web UIの起動:
- Web UIを起動し、ブラウザからアクセスします。
python webui.pyこれで、ローカル環境でStable Diffusionを利用する準備が整います。
Stable Diffusionは、テキストから高品質な画像を生成するAIモデルで、多様なスタイルの画像生成や既存画像の編集も可能です。利用方法はオンラインサービス、クラウドストレージ、ローカル環境の3通りがあり、各方法のメリット・デメリットを考慮して選択できます。ローカル環境での利用には、PythonとGitのインストールが必要ですが、自由度の高いカスタマイズが可能です。
Stable Diffusion AIの仕組み

Stable Diffusion AIは革新的な画像生成技術を用いた人工知能システムです。その仕組みは、大規模な画像データセットを学習し、潜在空間と呼ばれる低次元の表現を用いて効率的に画像を生成します。
画像生成のプロセスは以下のようになっています:
- テキスト入力: ユーザーが生成したい画像の説明を入力
- エンコーディング: 入力テキストを数値ベクトルに変換
- 潜在空間での処理: ノイズから徐々に画像の特徴を形成
- デコーディング: 潜在表現から実際の画像ピクセルを生成
Stable Diffusion AIの特徴として、オープンソースで公開されていることが挙げられます。これにより、透明性が高まり、研究者や開発者がモデルの挙動を検証し改善できます。また、企業や個人が独自のニーズに合わせてカスタマイズすることも可能です。
セキュリティ面では、以下のような対策が講じられています:
- データの匿名化: 学習データから個人情報を除去
- アクセス制御: APIキーなどによる利用者の認証
- コンテンツフィルタリング: 不適切な画像生成の防止
- モデルの監査: 定期的なセキュリティチェック
これらの対策により、Stable Diffusion AIはプライバシーや著作権の問題に配慮しつつ、革新的な画像生成技術を提供しています。今後も技術の進化とともに、さらなるセキュリティ強化が期待されます。
Stable Diffusion AIのテキスト画像生成モデルの利用
Stable Diffusionは、テキストから高品質な画像を生成できる革新的なAIモデルです。その特長と仕組み、使い方について解説します。
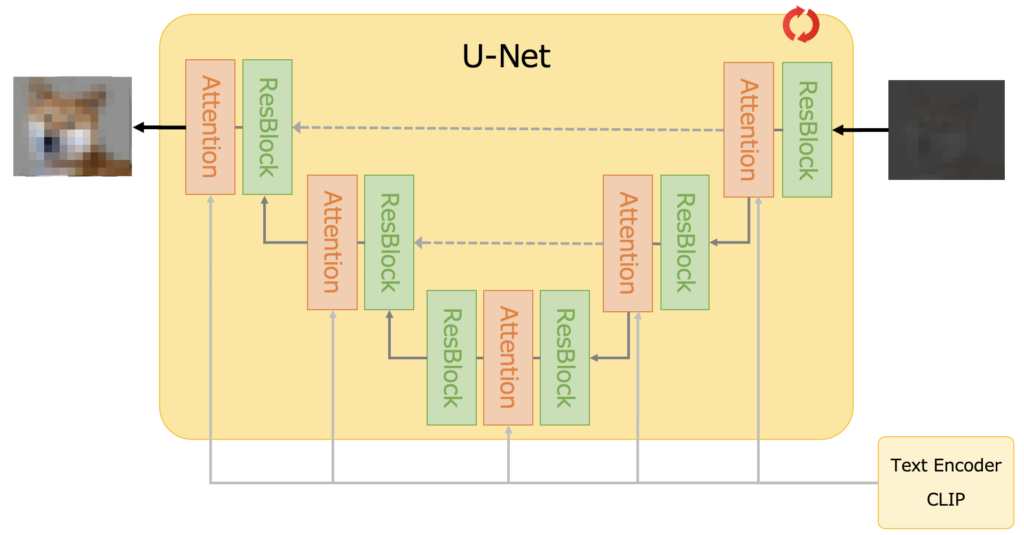
Stable Diffusionの特長
- オープンソースで無料で利用可能
- 高品質な画像生成が可能
- ローカル環境で動作可能
- 商用利用も可能(一部制限あり)
- 多様なモデルやプロンプトの組み合わせで無限の可能性
仕組み
Stable Diffusionは潜在拡散モデル(Latent Diffusion Model)を採用しています。主な構成要素は以下の通りです:
- テキストエンコーダー: 入力テキストを埋め込みベクトルに変換
- 画像生成器:
- 拡散プロセス: 画像にノイズを徐々に追加
- 逆拡散プロセス: ノイズを除去しながら画像を生成
- 画像デコーダー: 生成された潜在表現を最終的な画像に変換
この過程で、クロスアテンション技術を用いてテキストと画像の整合性を高めています。
使い方
- Webアプリケーション(Hugging Face、Dream Studioなど)またはローカル環境を選択
- プロンプト(生成したい画像の説明)を入力
- オプション設定(画像サイズ、生成数など)
- 生成ボタンをクリック
- 結果を確認し、必要に応じてプロンプトを調整
効果的な使用のコツ
- 具体的で詳細なプロンプトを使用
- スタイルや雰囲気を指定(例: “photorealistic”, “oil painting”)
- 否定的プロンプトで不要な要素を除外
- 異なるモデルを試す
- シードを固定して再現性を確保
商用利用の注意点
- ライセンスの確認が必要
- 著作権や肖像権に注意
- AIが生成した画像の著作権は不明確な部分あり
Stable Diffusionは、クリエイティブな作業やビジネスに革命をもたらす可能性を秘めています。適切に使用すれば、画像制作の効率を大幅に向上させることができるでしょう。
Stable Diffusion AIの日本語対応
日本語対応の重要性
Stable Diffusion AIの日本語対応は、日本市場における普及と受け入れを加速する上で非常に重要です。日本語は独自の文法や表現が多く、英語が苦手なユーザーにとっては、英語表記のままでは利用が難しいことがあります。日本語対応により、より多くの日本人ユーザーが直感的に利用できるようになり、画像生成AIの利用が広がることが期待されます。
日本語対応がもたらすメリット
- ユーザビリティの向上: 日本語対応により、ユーザーは英語の壁を感じることなく、直感的に操作できるようになります。
- 市場拡大: 日本語対応により、日本市場での利用者が増え、ビジネスチャンスが広がります。
- クリエイティブの促進: 日本語でのプロンプト入力が可能になることで、より多様な表現が可能となり、クリエイティブな作品が生まれやすくなります。
日本語対応の進化
Stable Diffusionの日本語対応は、以下のように進化してきました。
- 拡張機能の利用: 初期段階では、拡張機能を利用して日本語化する方法が一般的でした。これにより、英語が苦手なユーザーでも利用しやすくなりました。
- 日本語特化モデルの開発: 最近では、Japanese Stable Diffusionのように、日本語に特化したモデルが開発され、より高精度な日本語対応が実現されています。
- 高速化と効率化: 日本のスタートアップ企業が開発したSakana AIの「EvoSDXL-JP」モデルは、日本語対応の推論速度を大幅に向上させ、より迅速な画像生成が可能となっています。
日本語対応の進化の例
以下の表は、Stable Diffusionの日本語対応の進化を示しています。
| 時期 | 進化の内容 | 具体例 |
|---|---|---|
| 初期 | 拡張機能の利用 | WebUIの日本語化[5] |
| 中期 | 日本語特化モデルの開発 | Japanese Stable Diffusion[3] |
| 現在 | 高速化と効率化 | EvoSDXL-JPモデル[4] |
Stable Diffusion AIの日本語対応は、ユーザビリティの向上や市場拡大、クリエイティブの促進など多くのメリットをもたらしています。拡張機能の利用から日本語特化モデルの開発、さらには高速化と効率化といった進化を遂げており、今後もさらなる発展が期待されます。
Stable Diffusion AIの活用事例
Stable Diffusion AIは、様々な業界で革新的な活用事例を生み出しています。以下に、代表的な事例をいくつか紹介します。
広告・マーケティング分野での活用
広告業界では、Stable Diffusion AIを使用して斬新なキャンペーンやプロモーション材料を作成しています。
- 大手通信会社のCMで、過去のシリーズCMからシーンを抽出し、AIによってアニメーション化
- 大手ビールメーカーによる、顧客参加型の画像生成プロモーション
- 地方テレビ局によるAI生成イメージを活用したCM制作
これらの事例は、AIによって生成された画像やアニメーションを効果的に活用し、視聴者の注目を集めることに成功しています。
エンターテインメント業界での応用
映画やゲーム業界でも、Stable Diffusion AIの活用が進んでいます。
- 映画制作における背景やコンセプトアートの生成
- ゲームシーンやキャラクターデザインの素案作成
- アニメや3DCGの再現や新規制作
AIを活用することで、クリエイティブプロセスの効率化や、新しい表現の可能性が広がっています。
製品開発とビジュアライゼーション
製品開発やデザイン分野でも、Stable Diffusion AIは重要なツールとなっています。
- 自動車メーカーによる未来のモビリティコンセプトの視覚化
- 食品サンプルのデザイン案生成
- 建築や都市計画におけるランドスケープイメージの作成
AIによって生成されたイメージは、アイデアの具現化や、プレゼンテーションの質の向上に貢献しています。
その他の興味深い活用例
- AI influencerの創出:仮想のインフルエンサーを生成し、マーケティングに活用
- 写真合成:既存の写真と組み合わせて新しいビジュアルを作成
- ビジュアル調整:既存の画像やデザインの色調や雰囲気を変更
これらの事例は、Stable Diffusion AIの柔軟性と多様な応用可能性を示しています。
以上の活用事例から、Stable Diffusion AIが創造性を刺激し、ビジネスプロセスを効率化する強力なツールであることがわかります。今後も、さらに多くの革新的な使用方法が登場することが期待されます。
Stable Diffusion AIの影響について

概要
Stable Diffusionは、テキストから画像を生成するオープンソースのAIモデルです。この技術は、ユーザーが入力したテキストに基づいて高品質な画像を生成することができます。これにより、クリエイティブなプロジェクトやビジネス用途での画像生成が簡単に行えるようになりました。
環境への影響
Stable Diffusionのような生成AIモデルは、動作に大量の計算資源を必要とします。これにより、エネルギー消費が増加し、環境への影響が懸念されています。以下の図は、生成AIモデルのエネルギー消費量とその環境への影響を示しています。
| モデル | エネルギー消費 (kWh) | CO2排出量 (kg) |
|---|---|---|
| Stable Diffusion | 0.1 | 0.06 |
| Midjourney | 0.15 | 0.09 |
| DALL-E | 0.2 | 0.12 |
この表からわかるように、Stable Diffusionは比較的エネルギー効率が良いですが、それでも環境への影響は無視できません。特に、大規模な生成タスクを頻繁に行う場合、エネルギー消費とCO2排出量が増加します。
社会への影響
Stable Diffusionの普及は、社会に多大な影響を与えています。以下にその主な影響を示します。
クリエイティブ産業への影響
- 効率化: 画像生成のプロセスが自動化され、クリエイティブな作業が効率化されました。
- 新たな表現の可能性: アーティストやデザイナーは、AIを活用して新しい表現方法を探索することができます。
労働市場への影響
- 職業の変化: 画像生成AIの普及により、従来のイラストレーターやデザイナーの仕事が減少する可能性があります。
- 新たなスキルの需要: AIを活用した新しいスキルや知識が求められるようになります。
倫理的・社会的課題
- 著作権問題: AIが生成した画像の著作権や使用権に関する問題が浮上しています。
- フェイクコンテンツの増加: AIによる画像生成が容易になることで、フェイクコンテンツの増加が懸念されています。
Stable Diffusionは、画像生成の分野において革新的な技術を提供していますが、その普及には環境への影響や社会的な課題も伴います。これらの問題に対処するためには、エネルギー効率の向上や倫理的なガイドラインの整備が必要です。
Stable Diffusion AIの統合機能
Stable Diffusion AIの機能統合は、画像生成の分野に革新をもたらしています。最新バージョンのStable Diffusion 3では、複数のテキストエンコーダーとMultimodal Diffusion Transformer (MMDiT)の導入により、より高度で柔軟な画像生成が可能になりました。
この進化により、以下のような利点が生まれています:
- 高品質な画像生成: より詳細でリアルな画像の生成が可能に
- 多様な表現: 複数のエンコーダーにより、様々なスタイルや概念の表現が向上
- 処理速度の向上: 最適化された推論速度により、迅速な画像生成が実現
- メモリ効率の改善: 様々なハードウェアでの実行が可能に
さらに、Stable Diffusion 3は将来的な拡張性も考慮されています。今後予想される進化の方向性としては:
- マルチモーダル対応: 画像だけでなく、動画、3D、音声などへの拡張
- リアルタイム処理: さらなる高速化によるリアルタイムでの画像生成
- カスタマイズ性の向上: ユーザー固有のニーズに合わせたファインチューニング機能の強化
これらの進化により、Stable Diffusion AIは単なる画像生成ツールから、クリエイティブワークフロー全体を変革する統合プラットフォームへと発展していく可能性があります。
以下は、Stable Diffusion AIの機能統合の進化を示す概念図です:
[高度な画像生成]
↑
[複数テキストエンコーダー] → [MMDiT] → [最適化エンジン]
↓
[マルチモーダル対応] [リアルタイム処理] [カスタマイズ]
↓
[統合AIプラットフォーム]この進化により、クリエイティブ産業やビジネス分野に大きな変革をもたらすことが期待されています。





