
Stable Diffusion AI の魔法への扉を開く新たな冒険
Diffusion-webuiの機能と魅力
Stable Diffusionは、テキストから画像を生成する強力なAIツールとして注目を集めています。その中でもDiffusion-webuiは、使いやすいインターフェースと豊富な機能で人気を博しています。
Diffusion-webuiの主な魅力は以下の点にあります:
- 直感的なウェブインターフェース
- 多彩な画像生成オプション
- モデルの切り替えが容易
- 拡張機能による機能拡張性
- バッチ処理による効率的な生成
初心者にとっては、以下の点から始めるのがおすすめです:
- 基本的なプロンプト入力から始める
- 徐々にパラメータを調整してみる
- 公開されているプロンプト例を参考にする
- コミュニティで情報交換する
Stable Diffusionのモデルは日々進化しており、注目のモデルとしては:
- Anything V5 – アニメ調の生成に強い
- Realistic Vision V5 – リアルな画像生成が得意
- DreamShaper – バランスの取れた汎用モデル
などが挙げられます。
モデルの人気ランキングを見ると:
- Anything V5
- Realistic Vision V5
- DreamShaper
- ChilloutMix
- AbyssOrangeMix3
といった順になっています。
以下は主要モデルの評価をまとめた表です:
| モデル名 | 画質 | 汎用性 | 特徴 |
|---|---|---|---|
| Anything V5 | ★★★★☆ | ★★★☆☆ | アニメ調に強い |
| Realistic Vision V5 | ★★★★★ | ★★★★☆ | リアルな画像生成 |
| DreamShaper | ★★★★☆ | ★★★★★ | バランスが良い |
| ChilloutMix | ★★★★☆ | ★★★☆☆ | 独特な雰囲気 |
Stable Diffusionは日々進化を続けており、新しいモデルや機能が次々と登場しています。初心者から上級者まで、自分に合ったモデルや設定を見つけて楽しむことができるのが大きな魅力と言えるでしょう。
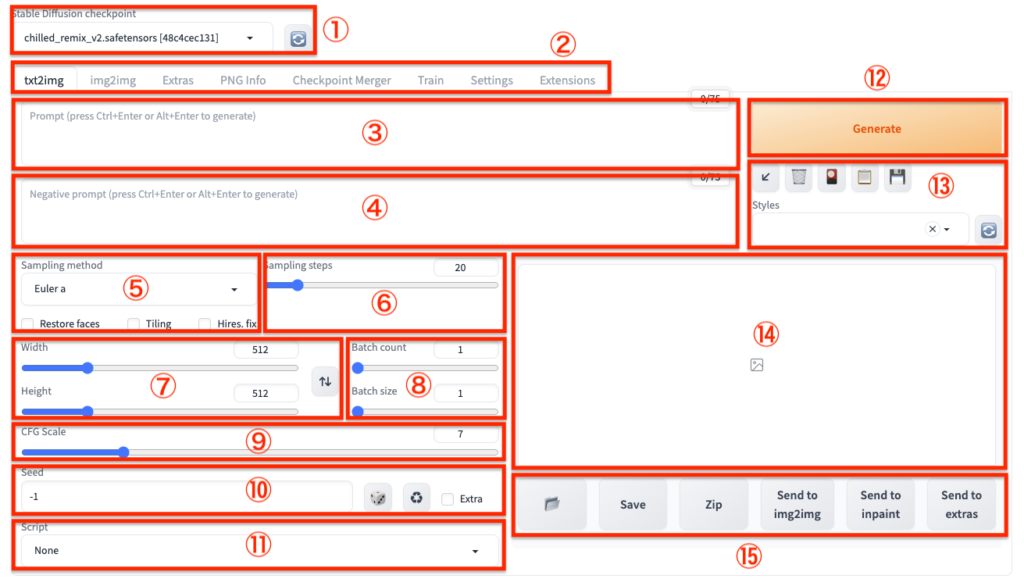
Stable Diffusionのセキュリティと除去方法
Stable Diffusionの安全性と活用について、以下のポイントが重要です:
セキュリティ面では、ローカル環境での使用が最も安全です。Webブラウザ版を利用する場合は、信頼できるサイトのみを使用し、個人情報の入力には注意が必要です。また、生成された画像の著作権や肖像権にも留意しましょう。
UIは直感的で使いやすく設計されており、テキスト入力欄やパラメータ調整スライダーなどが配置されています。インストールは公式サイトからダウンロードして行いますが、必要なPythonライブラリなども自動でインストールされます。
Webブラウザ版では、拡散モデルのアルゴリズムがJavaScriptで実装されており、ブラウザ上で画像生成が行われます。ただし処理速度はローカル版に劣ります。
活用面では、イラスト制作やデザイン案出しなど幅広い用途があります。問題が発生した場合は、公式ドキュメントやコミュニティフォーラムで解決策を探るのが効果的です。また、定期的なアップデートで新機能追加や不具合修正が行われています。
以下に、Stable Diffusionの主な特徴をまとめた表を示します:
| 項目 | 内容 |
|---|---|
| セキュリティ | ローカル環境が最安全、Web版は注意が必要 |
| UI | 直感的で使いやすい設計 |
| インストール | 公式サイトから自動インストール |
| Webブラウザ版 | JavaScript実装、処理速度は劣る |
| 活用例 | イラスト制作、デザイン案出しなど |
| 問題解決 | 公式ドキュメント、コミュニティ活用 |
Stable Diffusionは日々進化を続けており、今後さらなる機能拡張や使いやすさの向上が期待されます。
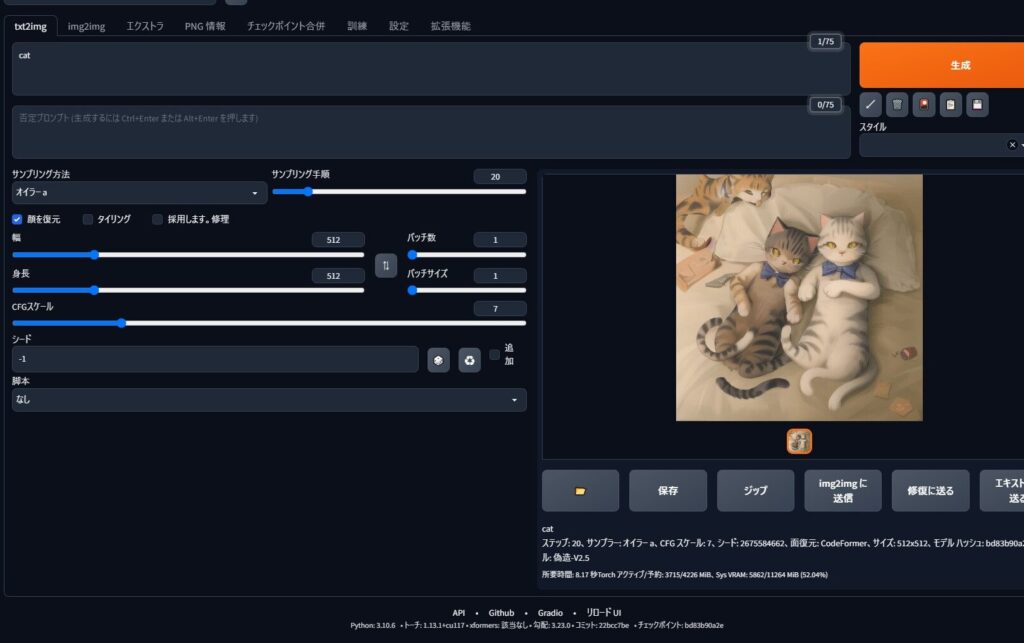
Stable Diffusionのデータ処理と理解
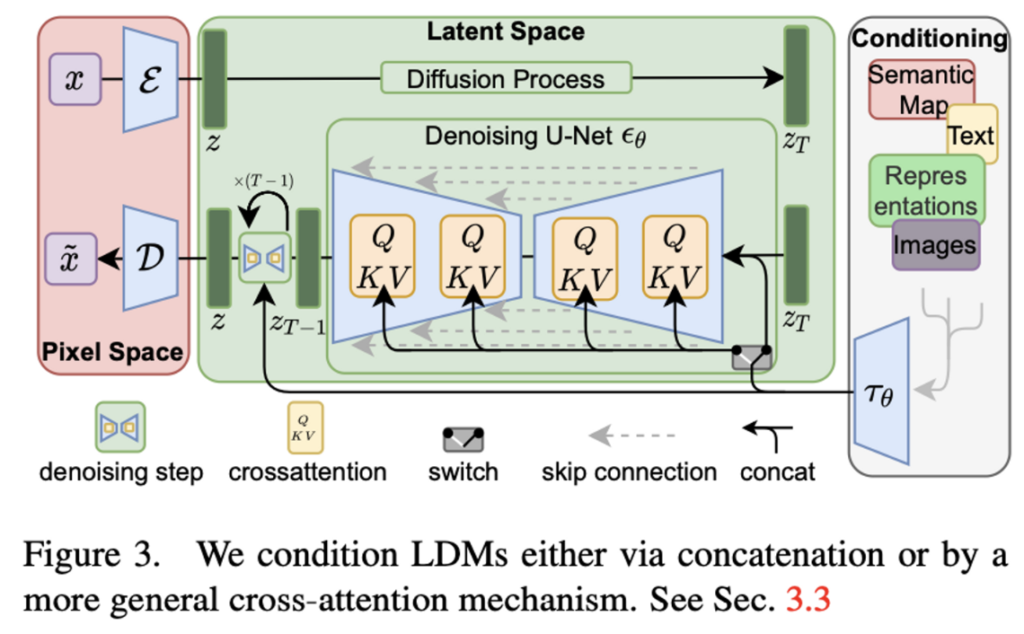
Stable Diffusionは、テキストから画像を生成する強力なAIモデルです。その核となる技術は拡散モデルと呼ばれるもので、ノイズを徐々に除去しながら画像を生成していきます。
データ処理の観点から見ると、Stable Diffusionは3つの主要なコンポーネントで構成されています:
- テキストエンコーダー: 入力テキストを数値表現に変換
- U-Net: 画像の生成を担当
- オートエンコーダー: 生成された画像を高解像度に変換
学習プロセスでは、大量の画像とそれに対応するキャプションデータを使用します。モデルは徐々にノイズを除去しながら、テキストの意味を反映した画像を生成する方法を学習していきます。
日本語モデルに関しては、日本語のテキストや画像データセットを用いて追加学習を行うことで、日本語に特化したモデルを作成できます。これにより、日本語の入力に対してより適切な画像生成が可能になります。
最近では、Stable Diffusionを応用してビデオ編集や生成も可能になってきています。例えば、フレーム間の補間や、テキストプロンプトに基づいた短いビデオクリップの生成などが実現されています。
以下は、Stable Diffusionの処理フローを簡略化したものです:
テキスト入力 → テキストエンコーダー → U-Net (ノイズ除去) → オートエンコーダー → 生成画像この技術は日々進化しており、今後はより高品質な画像生成や、より複雑なタスクへの応用が期待されています。
Stable Diffusionの構築と公開方法
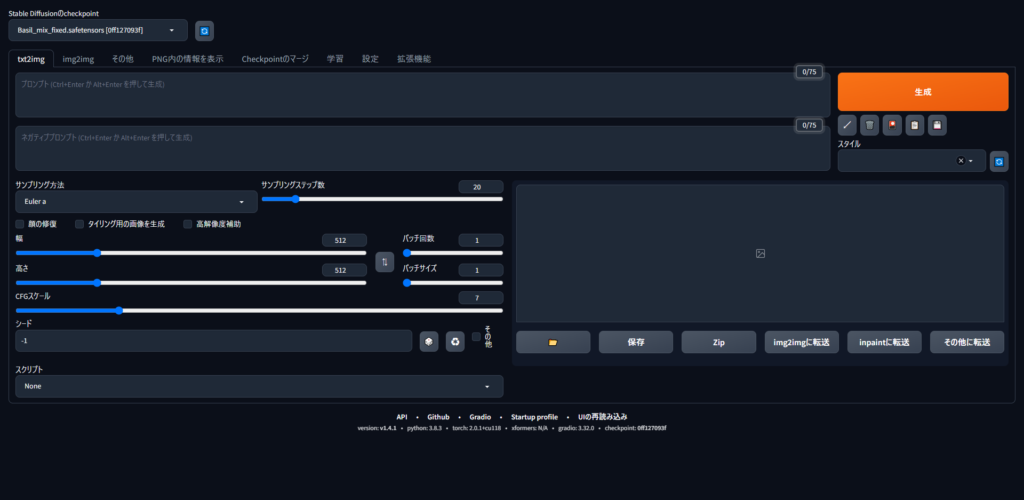
Stable Diffusionのデータモデル登録と活用について、以下のポイントを押さえておくと良いでしょう:
モデルのインストール
Stable Diffusionで新しいモデルを使用するには、以下の手順でインストールします:
- モデルファイル(.ckptまたは.safetensors)をダウンロード
- models/Stable-diffusionフォルダに配置
- Web UIを再起動
- モデル選択メニューから新しいモデルを選択
カスタムモデルの追加
独自のモデルを作成・追加する方法もあります:
- Dreambooth: 少量の画像から特定の被写体を学習
- Textual Inversion: 新しい概念やスタイルを学習
- LoRA: 軽量な追加学習モデル
これらの手法を使うことで、Stable Diffusionの出力をカスタマイズできます。
追加学習の実施
追加学習を行う際は以下の点に注意しましょう:
- 学習データの品質と量を確保する
- 過学習に注意し、適切な学習回数を設定する
- 元のモデルの特性を失わないよう調整する
モデルの活用
インストールしたモデルは以下のように活用できます:
- 画風の変更: アニメ調、写実的など
- 特定キャラクターの生成精度向上
- 背景や小物の表現力アップ
モデルを使い分けることで、多様な表現が可能になります。
以上のポイントを押さえつつ、目的に応じて適切なモデルを選択・活用することで、Stable Diffusionの可能性を最大限に引き出すことができるでしょう。
Stable Diffusionの安定性とシステム
Stable Diffusionは、テキストから画像を生成するための高度なAIモデルであり、その安定性と高品質な画像生成が特徴です。このモデルは、潜在拡散モデル(Latent Diffusion Model)を使用しており、ユーザーが入力したテキストを基に画像を生成します。
安定性の確保
Stable Diffusionは、以下の要素により高い安定性を実現しています:
- テキストエンコーダの使用:テキスト埋め込みを条件として利用することで、精度の高い画像生成を可能にしています。
- 安全性チェッカー:訓練データに存在するバイアスや誤解を反映しないように、安全性チェッカーモジュールを組み込んでいます。
Stable Diffusionの更新と運用対策
更新
Stable Diffusionは、継続的に更新されており、最新の技術やアルゴリズムが取り入れられています。特に、メモリ管理や画像生成の効率化に関する改善が行われています。
運用対策
Stable Diffusionを運用する際には、以下の対策が推奨されます:
- VRAMの最適化:画像生成時に必要なVRAMを効率的に使用するための設定が重要です。例えば、GPUメモリの再利用や断片化防止の設定を行うことで、メモリ不足を防ぐことができます。
- 低VRAMモードの利用:VRAMが不足する場合には、
--medvramや--lowvramオプションを使用して、CPU RAMを活用する方法もあります。
Stable Diffusionの日本市場への展開
Stability AIは、日本市場への展開を積極的に進めています。日本向けの大規模言語モデル(LLM)の開発や、スタートアップ企業の支援プログラムを通じて、ローカルな需要に応える取り組みを行っています。
日本市場での取り組み
- スタートアップ支援:日本のスタートアップ企業をサポートするプログラムを展開し、生成AIを活用した事業の変革を支援しています。
- ローカルニーズへの対応:大規模なプロジェクトだけでなく、実際的でローカルなニーズに柔軟に対応する方針を掲げています。
Stable Diffusionの開発と適用範囲
開発背景
Stable Diffusionは、テキストから画像への変換を行うために開発されました。開発の背景には、テキストエンコーダのテキスト埋め込みを条件とした潜在的な拡散モデルの需要がありました。
適用範囲
Stable Diffusionの適用範囲は広く、以下のような分野で活用されています:
- クリエイティブ業界:アートやデザインの自動生成。
- 広告業界:広告素材の自動生成。
- 教育分野:教育用コンテンツの生成。
- 研究開発:新しいアルゴリズムやモデルの検証[2]。
システム構成
Stable Diffusionは、Webアプリケーションやローカル環境で動作させることが可能です。例えば、Hugging FaceやDream StudioなどのWebアプリケーションを利用することで、簡単に画像生成を体験できます。
Stable Diffusionは、その安定性と高品質な画像生成能力により、さまざまな分野での応用が期待されています。日本市場への積極的な展開や、運用対策の充実により、今後さらに多くのユーザーに利用されることが予想されます。
Stable Diffusionの課題と調整

Stable Diffusionは画像生成AIの分野で急速な進化を遂げていますが、いくつかの課題と改善の余地があります。
主な課題としては:
- 生成画像の一貫性と精度の向上
- 著作権や倫理的問題への対応
- 計算リソースの最適化
これらに対して、以下のような調整や改善が行われています:
- LoRAやControlNetなどの追加学習技術の導入
- プロンプトエンジニアリングの高度化
- ハードウェア最適化とモデルの軽量化
Stable Diffusionの進化と応用面では:
- リアルタイム修正機能の実装
- 3D生成や動画生成への拡張
- 産業デザインやファッション分野での活用
ライバルモデルとの比較:
| モデル | 特徴 |
|---|---|
| Midjourney | 高品質だが柔軟性に欠ける |
| DALL-E | テキスト理解力が高い |
| Stable Diffusion | オープンソースで拡張性が高い |
モデル品質と性能調整においては:
- パラメータ数の増加 (XLモデルで35億パラメータ)
- マルチモーダル学習の導入
- ファインチューニング手法の改善
これらの取り組みにより、Stable Diffusionは画像生成の精度と多様性を向上させつつ、新たな応用分野を開拓しています。今後も技術革新と倫理的配慮のバランスを取りながら、さらなる発展が期待されます。





