AI画像生成に使えるStable Diffusionの概要
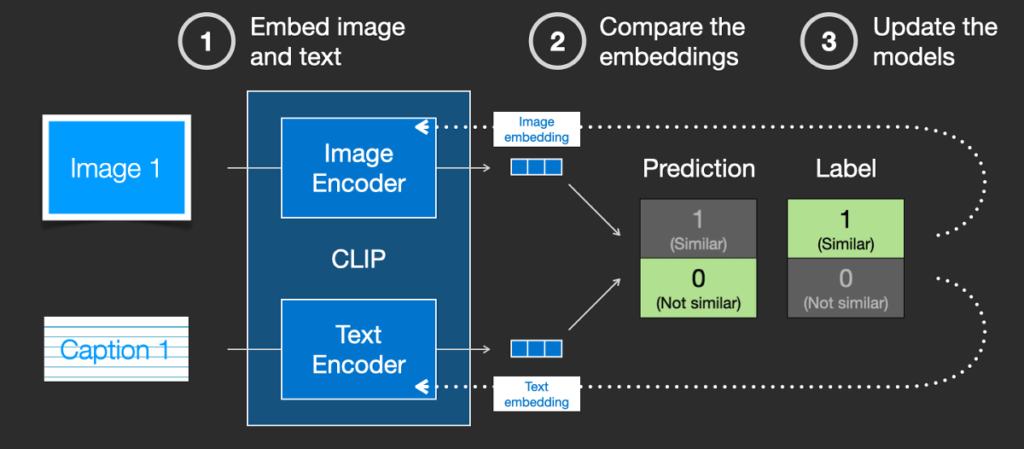
Stable Diffusionは、テキスト入力を基に画像を生成するディープラーニングモデルです。ミュンヘン大学のCompVisグループが開発し、Stability AI、CompVis LMU、Runwayの共同で公開されました。主に英語の説明文が付与された画像で学習されており、ユーザーは簡単なテキスト入力で多様な画像を生成できます。オープンソースであるため、誰でも利用可能です。
初心者向けのStable Diffusionの使い方
基本操作
- テキスト入力: 生成したい画像のイメージを英単語で入力します。例えば、「sunset over a mountain」など。
- インターフェースの選択: Hugging FaceやDream StudioなどのWebアプリケーションを利用するか、ローカル環境にインストールして使用します。
- カスタムオプション: 各インターフェースには細かな設定オプションがあり、生成画像の品質やスタイルを調整できます。
利用方法の選択
| 利用方法 | メリット | デメリット |
|---|---|---|
| オンラインサービス | 環境構築不要、簡単に高品質な画像生成 | 機能が限られる、サーバー混雑時に遅延 |
| クラウドストレージ | 低スペックPCでも利用可能、速い生成速度 | 有料プランが必要、立ち上げに時間がかかる |
| ローカル環境 | 無料で無制限利用、自由にカスタマイズ可能 | 環境構築が手間、高スペックPCが必要 |
安全な使い方
商用利用の注意点
- 著作権: Stable Diffusionで生成された画像には著作権がありませんが、商用利用する際は、元データのライセンスを確認する必要があります。
- 不適切な利用の禁止: 法律や規制に違反する用途、未成年者の悪用、個人情報の生成や拡散は禁止されています。
安全なプロンプトの作成
- 具体的な指示: 明確で具体的な単語を使用し、生成したい画像の詳細を記述します。
- ネガティブプロンプト: 生成したくない要素を明示的に除外するためのプロンプトも入力します。
画像からノイズを除去する方法
Stable Diffusionでは、生成した画像のノイズを除去するためのオプションがいくつかあります。
ノイズ除去の設定
- Denoising strength: ノイズ除去の強度を設定します。デフォルトは0.7で、値を低くするとぼやけ、高くすると鮮明になりますが、元画像と異なるイメージになる可能性があります。
- Hires.fix: 高解像度でのノイズ除去を行う機能です。ステップ数やアップスケール倍率を調整して、元画像の品質を保ちながら高解像度化します。
設定例
| 設定項目 | 説明 | 推奨値 |
|---|---|---|
| Denoising strength | ノイズ除去の強度 | 0.7 |
| Hires steps | ノイズ除去の回数 | 10~20 |
| Upscale by | 画像拡大率 | 2 |
これらの設定を調整することで、ノイズを効果的に除去し、高品質な画像を生成できます。
Stable Diffusionは初心者でも簡単に利用できる画像生成AIで、適切な設定と注意点を守ることで、安全かつ効果的に利用できます。商用利用時の著作権や不適切な利用の禁止事項に注意しながら、クリエイティブな画像生成を楽しんでください。
Stable Diffusionをスムーズに使うための手順
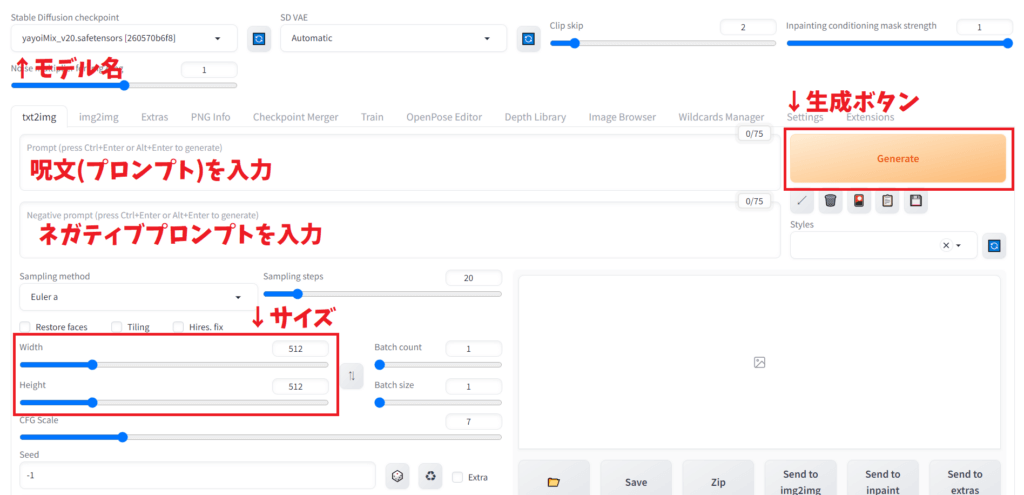
Stable Diffusionを快適に使うための手順は以下の通りです:
- 環境の準備
- 推奨スペック: CPU – 標準的なAMDまたはIntel、メモリ16GB以上、GPU 16GB VRAM以上、SSD 1TB以上
- Python、Git、Stable Diffusion Web UIのインストール
- Web UIの設定
- モデルのダウンロードと配置
- VAE、LoRA等の追加機能の導入
- 画像生成の基本手順
- プロンプトの入力(英語推奨)
- 生成設定の調整(サイズ、ステップ数等)
- 生成ボタンをクリック
- 便利な機能の活用
- img2img: 既存画像をベースに生成
- inpainting: 画像の一部を修正・置換
- ControlNet: ポーズや構図の制御
- プロンプトのコツ
- 重要なキーワードを前半に配置
- ()や[]で強調度を調整
- ネガティブプロンプトの活用
- 拡張機能の導入
- Easy Prompt Selector: プロンプト入力支援
- Additional Networks: LoRA等の管理
環境構築に手間はかかりますが、自由度の高い画像生成が可能になります。徐々に機能を追加しながら、理想の画像生成環境を作り上げていくことをおすすめします。
Diffusion AIの特徴的なモデル活用法

Stable Diffusionを使って画像を比較する方法には、いくつかの効果的なアプローチがあります。
最も一般的なのは、X/Y/Zプロット機能を活用する方法です。この機能を使うと、複数のパラメータやプロンプトを一度に比較できます。例えば、異なるモデル、サンプラー、ステップ数などを軸にして、それぞれがどのように画像生成に影響するかを視覚的に確認できます。
具体的な使い方としては:
- Stable Diffusion Web UIの「Script」セクションからX/Y/Zプロットを選択
- X軸、Y軸、Z軸にそれぞれ比較したいパラメータを設定
- 各軸の値を入力(例: モデル名、ステップ数など)
- 生成ボタンをクリックして比較画像を作成
この方法を使えば、一度に最大3つの要素を比較できる画像グリッドが生成されます。
また、プロンプトマトリックス機能も有用です。これを使うと、基本プロンプトに追加するキーワードの組み合わせを簡単に比較できます。プロンプトにパイプライン(|)を使って区切ることで、それぞれの組み合わせで画像が生成されます。
さらに、バッチ処理機能を使って同じプロンプトで複数の画像を生成し、後から比較することも可能です。これは微妙な違いを見たい場合に特に有効です。
これらの方法を組み合わせることで、効率的かつ体系的に画像を比較し、Stable Diffusionの挙動をより深く理解することができます。また、これらの比較結果を元に、自分の目的に最適なパラメータやプロンプトを見つけ出すことができるでしょう。
Diffusion AIによる画像の解説

Diffusion AIモデルは、画像生成において高い精度を誇る生成モデルの一つです。特に、Stable Diffusionはその代表例であり、テキストプロンプトから高品質な画像を生成することができます。Diffusionモデルは、画像に少しずつノイズを加え、そのノイズを除去して元の画像を復元するというプロセスを繰り返すことで、最終的に新しい画像を生成します。
Diffusion AIで画像の必要なデータを抽出する方法
Stable Diffusionを使用して画像から必要なデータを抽出する方法はいくつかあります。以下に代表的な方法を紹介します。
1. Interrogate CLIPとInterrogate DeepBooru
- これらのツールを使用すると、画像からテキストプロンプトを推定することができます。これにより、どのようなプロンプトが使用されたかを知ることができます。
2. Tagger拡張機能
- Taggerを使用すると、画像から詳細なタグ情報を抽出できます。画像を解析し、関連するキーワードやタグを生成します。
3. PNG Info
- 画像のメタデータにプロンプト情報が含まれている場合、PNG Infoを使用してその情報を表示することができます。
Diffusion AIモデルを使っての画像の演出
Stable Diffusionを使用して画像を生成・編集する方法は多岐にわたります。以下に主な機能を紹介します。
1. txt2img
- テキストプロンプトを入力することで、指定された内容に基づいた画像を生成します。
2. img2img
- 既存の画像を元に、新しい画像を生成します。元画像のスタイルや構図を保持しつつ、異なる要素を追加することができます。
3. Inpainting
- 画像の一部を修正する機能です。特定の部分を選択して、その部分だけを新しい内容に置き換えることができます。
4. Outpainting
- 画像の外側に新しい内容を追加する機能です。画像の構図を拡張する際に使用されます。
Stable Diffusionモデルの除去を行う方法
Stable Diffusionモデルや生成された画像を削除する方法は以下の通りです。
1. ターミナルを使用した削除
- ターミナルを使用して、特定のフォルダやファイルを削除することができます。以下のコマンドを使用します。
rm -r /path/to/folder2. Lama Cleaner拡張機能
- Lama Cleanerを使用すると、生成された画像から不要な要素を削除することができます。以下の手順でインストールします。
- Stable Diffusion Web UIを立ち上げ、「Extensions」タブ→「Install from URL」タブを開きます。
- URLフィールドに以下のURLを入力し、「Install」ボタンをクリックします。
url https://github.com/aka7774/sd_lama_cleaner.git - 「Installed」タブを開き、「Apply and restart UI」ボタンをクリックします。
Diffusion AIモデル、特にStable Diffusionは、テキストプロンプトから高品質な画像を生成する強力なツールです。画像から必要なデータを抽出するためのツールや、生成された画像を編集するための機能も豊富に揃っています。また、不要なモデルや画像を削除するための方法も簡単に実行できます。これらの機能を駆使することで、より効果的に画像生成AIを活用することができます。
Diffusion AIのオプション機能の使い方

Stable Diffusionは、テキストプロンプトから画像を生成するための強力なAIツールです。以下に、Diffusion AIのオプション機能の使い方、Stable DiffusionUIを使用したノイズ除去方法、動画の操作方法、そしてStable Diffusionモデルの実行方法について詳しく説明します。
Diffusion AIのオプション機能の使い方
Stable Diffusionには多くのオプション機能があり、ユーザーはこれらを活用して生成画像の品質やスタイルを調整できます。主なオプション機能には以下のようなものがあります:
- プロンプトの詳細設定:生成したい画像の具体的な内容を詳細に設定することで、より精度の高い画像を生成できます。
- CFG Scale:プロンプトの指示に対する厳密さを調整するパラメータです。値を高くするとプロンプトに忠実な画像が生成されますが、低くすると自由度が増します。
- Steps:画像生成のステップ数を設定します。ステップ数が多いほど詳細な画像が生成されますが、時間もかかります。
- Seed:ランダムシードを設定することで、同じプロンプトでも異なる画像を生成できます。
Stable DiffusionUIの機能を使い、ノイズを除去する方法
Stable DiffusionUIを使用してノイズを除去する方法は以下の通りです:
- Denoising Strengthの設定:ノイズ除去の強度を調整するパラメータです。デフォルト値は0.7ですが、値を大きくするとノイズがより除去されます。ただし、画像がぼやける可能性もあります[4][13]。
- Sampling Steps:ノイズを除去する回数を設定します。一般的には20〜30ステップがバランスの取れた結果をもたらします[14]。
- Hires.fixの利用:高解像度の画像を生成するための機能で、ノイズを除去しながら画像をアップスケールします[13]。
Stable Diffusionアプリが使える動画の操作
Stable Diffusionを使って動画を生成するには、Stable Video Diffusionという拡張機能を使用します。この機能は以下の手順で利用できます:
- 画像のアップロード:動画化したい画像をWeb UI上にアップロードします[6]。
- プロンプトの設定:動画の内容を詳細に設定するためのプロンプトを入力します。これにより、動画の各フレームが生成されます[15]。
- 時間畳み込みの利用:Stable Video Diffusionは時間畳み込みを利用して、フレーム間の一貫性を保ちながら動画を生成します[6]。
Stable Diffusionモデルの実行方法
Stable Diffusionモデルを実行する方法は以下の通りです:
- ローカル環境の構築:
- PythonとGitのインストール:Python 3.10.6とGitをインストールします[10]。
- 必要なライブラリのインストール:
condaやpipを使用して必要なライブラリをインストールします[8]。 - モデルのダウンロード:Stable Diffusionのモデルファイルをダウンロードし、設定します[8][10]。
- オンラインツールの利用:
- DreamStudio:Stability AIが提供するオンラインツールで、簡単に画像を生成できます[10]。
- Hugging Face:オープンソースのコミュニティプラットフォームで、Stable Diffusionモデルを無料で利用できます[10]。
- Google Colabの利用:Google Colabを使用して、クラウド上でStable Diffusionを実行することも可能です。これにより、高性能なGPUを利用して画像生成が行えます[5][12]。
これらの方法を活用することで、Stable Diffusionを効果的に利用し、さまざまなクリエイティブなプロジェクトに応用することができます。
Stable Diffusionでの画像生成プロセスの評価
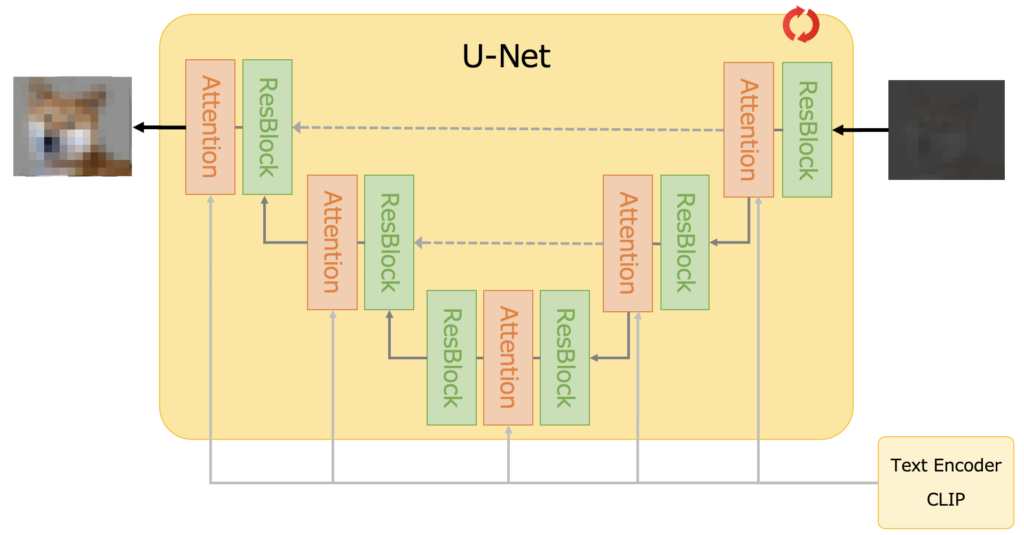
Stable Diffusionは、テキストから高品質な画像を生成するための高度なAIモデルです。このモデルは、拡散モデル(Diffusion Model)を基盤としており、以下のようなプロセスで画像を生成します。
- テキストエンコーダー:ユーザーが入力したテキスト(プロンプト)を理解し、768次元のトークン埋め込みベクトルに変換します。
- 画像情報クリエイター:初期のざっくりとした画像を生成し、ノイズを繰り返し追加します。
- 逆拡散プロセス:ノイズを徐々に除去し、詳細なディテールを加えていきます。この過程で、AIはテキストの意味を解析し、それに基づいて画像を具体化します。
- 画像デコーダー:最終的に高解像度の画像を生成します。
このプロセスにより、Stable Diffusionは非常にリアルで詳細な画像を生成することが可能です。
Webブラウザからの動画の作成手順
Stable Video Diffusionは、Stable Diffusionの技術を応用した動画生成AIです。以下の手順でWebブラウザから動画を作成できます。
- Google Colabのノートブックを開く:サンプルコードのノートブックをGoogle Colabで開きます。
- コードを実行:ノートブック内のコードを実行します。
- Web UIの起動:実行後に表示されるリンクをクリックして、Stable Video DiffusionのWeb UIを起動します。
- 画像のアップロード:動画化したい画像をWeb UIにアップロードします。
- 動画生成:必要な設定を行い、動画生成を開始します。数分で動画が完成します。
Stable Diffusionの画像処理
Stable Diffusionには、既存の画像を編集・変換するための機能も備わっています。
- img2img:既存の画像を元に新たな画像を生成する機能です。元画像のサイズや質を維持しつつ、プロンプトに基づいて新しい画像を生成します。
- inpaint:画像の一部を修正・変更する機能です。背景やアイテム、四肢のエラーなどを修正できます。
- HakuImg:画像のオフセット照射、ノイズ、色相、コントラスト補正など、多機能な画像編集ツールです。
Stable Diffusionのレビューランキングを利用した画像の作成
Stable Diffusionを利用して、レビューランキングに基づいた画像を生成することも可能です。以下の手順で行います。
- レビューランキングの収集:生成したい画像に関連するレビューランキングを収集します。
- テキストプロンプトの作成:ランキングに基づいて、適切なテキストプロンプトを作成します。例えば、「トップレビューの風景写真」など。
- 画像生成:Stable Diffusionにテキストプロンプトを入力し、画像を生成します。
- 評価と調整:生成された画像を評価し、必要に応じてプロンプトを調整して再生成します。
Stable Diffusionは、テキストから高品質な画像を生成するための強力なツールであり、動画生成や画像編集にも応用できます。レビューランキングを利用した画像生成も可能で、幅広いクリエイティブな用途に対応しています。以下の図は、Stable Diffusionの画像生成プロセスを視覚的に示したものです。
Stable Diffusionの画像生成プロセス
このように、Stable Diffusionは多機能で高性能な画像生成AIとして、多くの分野で活用されています。