
Stable DiffusionAIを利用した、プロの画像・映像クリエイターへの道
Diffusion WebUIを使いこなす基本機能の使い方
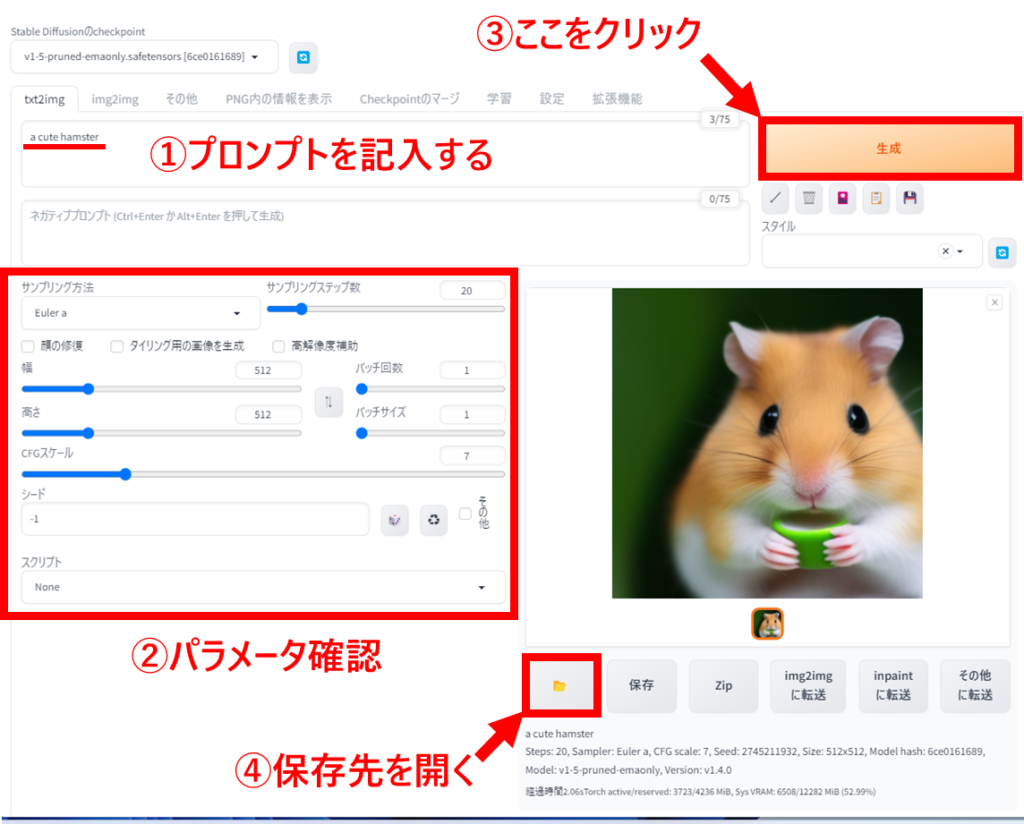
Stable Diffusion WebUIとは?
Stable Diffusion WebUIは、ブラウザを通じて画像生成AI「Stable Diffusion」を簡単に利用できるインターフェースです。AUTOMATIC1111版やForge版などがあり、プログラミングの知識がなくても視覚的に操作できます。
インストールと起動方法
- インストール: GitHubからStable Diffusion WebUIのリポジトリをクローンし、必要な依存関係をインストールします。
- 起動:
webui-user.batファイルを実行し、ブラウザでWebUIにアクセスします。自動起動するには、--autolaunchオプションを追加します。
基本機能
- txt2img: テキストプロンプトから画像を生成します。
- img2img: 既存の画像を元に新しい画像を生成します。
- 設定: モデルの選択やVAEの設定、Clip Skipの数値などを調整できます。
- 拡張機能: 様々な拡張機能をインストールして機能を追加できます。
おすすめ設定
- モデルの選択:
sd_model_checkpoint - VAEの選択:
sd_vae - Clip Skipの数値:
CLIP_stop_at_last_layers - PNG情報の保存:
enable_pnginfo
画像生成のコツ
プロンプトの使い方
- 要素ごとにBREAKを入れる: 例えば、髪型、服装、背景などを区切って入力することで、各要素が干渉せずに生成されます。
- 品質向上プロンプト:
masterpiece, high quality, 4K, HDRなどを使うことで、生成される画像の品質を向上させます。 - ネガティブプロンプト: 不要な要素を排除するために使用します。
プロンプトの例
masterpiece, high quality, 4K, HDR BREAK pink hair, braid hair BREAK smile, happy, red cheek BREAK school uniform BREAK dynamic pose, from above, upper body BREAK school background動画生成の方法
Stable Video Diffusion
Stable Video Diffusionは、Stable Diffusionの技術を応用して動画を生成するツールです。画像生成と同様に、テキストや画像を入力することで動画を生成します。
使い方
- テキスト入力: 動画の内容をテキストで指定します。
- 画像入力: 既存の画像を元に動画を生成します。
- 生成: 指定した内容に基づいて動画が生成されます。
Stable Diffusion WebUIを使えば、簡単に高品質な画像や動画を生成することができます。プロンプトの使い方や設定を工夫することで、より自分のイメージに近い生成物を得ることができます。初心者でも使いやすいインターフェースと豊富なカスタマイズオプションが魅力です。
初心者にもわかりやすいStable Diffusion aiの使い方
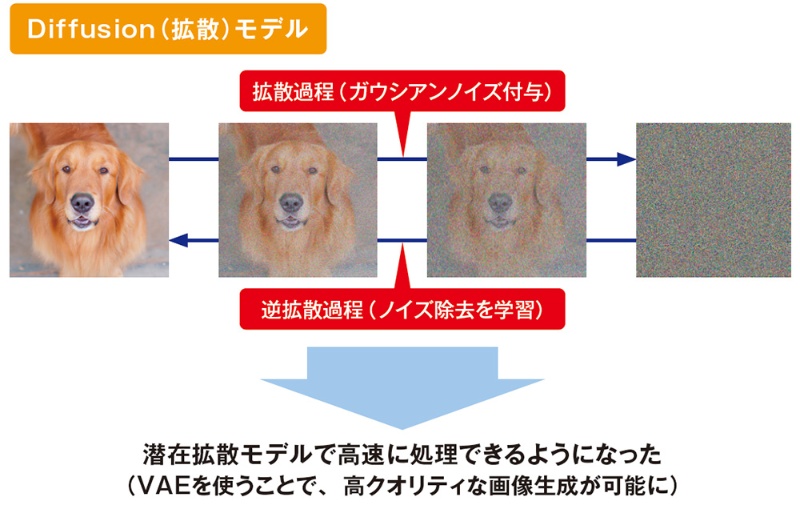
Stable Diffusionは、テキスト入力をもとに高品質な画像を生成するAIツールです。初心者でも簡単に使えるように設計されており、以下のガイドではその基本的な使い方、画像からの除去拡散(inpainting)、およびサポート体制について詳しく説明します。
Stable Diffusionの基本的な使い方
利用方法の選択
Stable Diffusionを利用する方法は主に以下の3つです:
- オンラインサービス(例:Stable Diffusion Online、DreamStudio)
- クラウドストレージ(例:Google Colaboratory)
- ローカル環境(自分のPCにインストール)
それぞれのメリットとデメリットを以下の表にまとめました。
| 利用方法 | メリット | デメリット |
|---|---|---|
| オンラインサービス | 環境構築が不要、無料で利用可能 | 機能が限られている、サーバー混雑時に遅くなる |
| クラウドストレージ | 低スペックPCでも利用可能、準備が少ない | 有料プランが必要、立ち上げに時間がかかる |
| ローカル環境 | 無料で無制限に利用可能、カスタマイズ自由 | 環境構築が手間、高スペックPCが必要 |
プロンプトの入力
画像生成の大部分はプロンプト(テキスト入力)に依存します。以下のポイントに注意してプロンプトを入力します:
- 単語の順番に気を付ける
- カンマと半角スペース(, )を使用して単語を区切る
- ネガティブプロンプトを使用して不要な要素を排除する
例:A beautiful sunset over the ocean, high resolution, vibrant colors
画像からの除去拡散(Inpainting)
Stable Diffusionには、生成された画像の一部を修正・除去するためのinpainting機能があります。これにより、画像の一部をマスクして新しい要素を追加したり、不要な部分を削除したりできます。
基本的な手順
- 画像とマスクの準備:修正したい画像と、修正部分を白、保持部分を黒で示すマスク画像を用意します。
- プロンプトの入力:修正後の画像のイメージをプロンプトとして入力します。
- 実行:inpainting機能を使用して画像を生成します。
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained("runwayml/stable-diffusion-inpainting")
prompt = "A park bench without any people"
image = pipe(prompt=prompt, image=image, mask_image=mask_image).images
image.save("output.png")Lama Cleanerの使用
Lama Cleanerは、Stable Diffusionの拡張機能で、画像の不要な要素を除去するのに役立ちます。
- Stable Diffusion Web UIを立ち上げる
- Extensionsタブ → Install from URLタブを開く
- URL for extension’s git repositoryに以下のURLを入力し、インストール
https://github.com/aka7774/sd_lama_cleaner.git- Apply and restart UIボタンをクリックして再起動
初心者向けのサポート体制
オンラインリソース
- 公式ドキュメント:Stable Diffusionの公式サイトやGitHubリポジトリには詳細なドキュメントが用意されています。
- チュートリアル動画:YouTubeなどで多くのチュートリアル動画が公開されています。
- コミュニティフォーラム:RedditやDiscordなどのコミュニティで質問や情報交換ができます。
有料プラン
- Google Colab Pro:月額1,179円で利用でき、より快適にStable Diffusionを使用できます。
トラブルシューティング
- エラーメッセージの確認:エラーメッセージを確認し、公式ドキュメントやコミュニティで解決策を探します。
- ハードウェアのアップグレード:高性能なGPUを使用することで、生成速度や品質が向上します。
Stable Diffusionは、初心者でも簡単に高品質な画像を生成できる強力なツールです。適切なプロンプトの入力やinpainting機能の活用、そして豊富なサポートリソースを利用することで、より効果的に使用することができます。
Stable Diffusion aiによる高品質な動画や画像の生成方法

高品質な動画生成のスペックと活用方法
Stable Diffusionを用いた動画生成には、以下のポイントが重要です:
- プロンプトの詳細設定:
- 動画生成の際に、プロンプトを詳細に設定することで、イメージに近い動画を生成しやすくなります。例えば、キャラクターの髪色や年齢、性別などを具体的に指定することが効果的です。
- 一貫性の確保:
- 動画の一貫性を保つために「reference only」機能を活用します。これにより、特定のフレームやシーンの一貫性を維持しやすくなります。
- 拡張機能の利用:
- mov2movなどの拡張機能を使用することで、動画生成の幅が広がります[1][2]。
人気のあるモデルの生成方法とその傾向
Stable Diffusionのモデルは、特定のスタイルやテーマに特化したものが多く存在します。以下は人気のあるモデルとその特徴です:
- 万象熔炉 | Anything XL:
- 高品質のアニメスタイル画像を生成するためのモデルで、商用利用も可能です。
- yayoi_mix:
- 日本のアニメやマンガ風の画像生成に特化したモデルです。
- MeinaUnreal:
- リアルな人物画像を生成するためのモデルで、特にポートレートに適しています。
Rev1の画像生成に向いているノイズの選択方法
Stable Diffusionの画像生成において、ノイズの選択は非常に重要です。以下のノイズスケジューラがよく使用されます:
- Euler a:
- 高速で安定した結果を得るために適しています。
- DPM++ SDE Karras:
- 高品質な画像生成に向いており、特に細部の表現に優れています。
- DDIM:
- 少ないステップ数で高品質な画像を生成するのに適しています。
まとめ
Stable Diffusionを用いた高品質な動画や画像の生成には、詳細なプロンプト設定、一貫性の確保、適切なモデルの選択、そして効果的なノイズスケジューラの選択が重要です。これらの要素を組み合わせることで、より高品質なコンテンツを生成することが可能です。
Stable Diffusion aiによる商用利用が始められる簡単な方法
Stable Diffusion AIは、テキストから高品質な画像を生成するオープンソースの画像生成AIであり、商用利用も可能です。以下に、商用利用の始め方、動画生成ツールの使い方、画像生成を使ったビジネスの可能性とメリットについて詳しく解説します。
商用利用の始め方
Stable Diffusionの商用利用を始めるには以下の手順を踏むと良いでしょう:
- ライセンスの確認:
- 商用利用が可能なモデルを使用することが重要です。商用利用不可のモデルや画像を使用すると法的な問題が生じる可能性があります[1][4][5]。
- 環境の設定:
- Webアプリケーションを利用する方法と、ローカル環境にセットアップする方法があります。Webアプリは簡単に始められますが、カスタマイズの自由度は低いです。ローカル環境では高い自由度が得られますが、設定が複雑です[5][6]。
- プロンプトの作成:
- テキストプロンプトを工夫して、生成したい画像の詳細を指定します。プロンプトの質が画像の質に大きく影響します[1][2]。
- 生成画像の利用:
- 生成した画像を商用利用する際には、著作権や肖像権に注意し、適切なライセンスを確認することが重要です[2][4][5]。
動画生成ツールの使い方
Stable Diffusionの技術を応用した動画生成ツール「Stable Video Diffusion」の使い方は以下の通りです:
- ツールの選択:
- Stable Video Diffusionは、画像やテキストから動画を生成するツールです。公式の実装やGitHub上のプロジェクトを利用して始めることができます[7][8][9]。
- 画像またはテキストの入力:
- 生成したい動画の元となる画像やテキストを入力します。例えば、画像をアップロードしてその内容に基づいた動画を生成します[9][12]。
- 動画の生成:
- 入力したデータに基づいて動画を生成します。生成された動画はダウンロードして商用利用することができます。ただし、商用利用の際にはライセンス条件を確認することが重要です[7][8][12]。
画像生成を使ったビジネスの可能性とメリット

Stable Diffusionを使った画像生成のビジネス活用には以下のような可能性とメリットがあります:
- クリエイティブなコンテンツ制作:
- 広告デザイン、ゲームや映画のコンセプトアート、SNSのアイコン、Webサイトやブログのキービジュアルなど、多岐にわたるクリエイティブな場面で活用できます。
- コスト削減と効率化:
- 短時間で高品質な画像を生成できるため、イラストレーターに発注するよりも安価で迅速にコンテンツを作成できます。
- 多様なスタイルの画像生成:
- リアル調、コミック調、ファンタジー調など、さまざまなスタイルの画像を生成できるため、幅広いニーズに対応可能です。
- 新しいビジネスモデルの創出:
- 生成した画像をアートワークとして販売したり、メタバース用のアバターを作成するなど、新しいビジネスモデルを構築することができます。
まとめ
Stable Diffusion AIは、商用利用が可能な高性能画像生成ツールであり、クリエイティブなコンテンツ制作やビジネスの効率化に大いに役立ちます。動画生成ツール「Stable Video Diffusion」も同様に、簡単に高品質な動画を生成できるため、映像制作やデザインの分野での活用が期待されます。商用利用の際には、ライセンス条件を確認し、法的な問題を避けることが重要です。
Stable Diffusion aiのランキングやレビューから注目のモデルを見つける方法
Stable Diffusion AIモデルの人気ランキングやレビューを活用して注目のモデルを見つける方法について解説します。
モデル探しの基本
Stable Diffusionのモデルを探す際は、主に以下の2つのサイトが参考になります:
- Civitai
- Hugging Face
これらのサイトでは、モデルのダウンロード数やユーザーレビューを確認できるため、人気のあるモデルを見つけやすくなっています。
ランキングを活用する
Civitaiでは、以下のようなランキング機能があります:
- 最も人気のあるモデル
- 最新のモデル
- 高評価のモデル
これらのランキングを定期的にチェックすることで、注目を集めている新しいモデルや、長期的に人気のあるモデルを見つけることができます。
レビューを確認する
モデルのレビューを読むことで、以下のような情報を得ることができます:
- モデルの特徴や得意分野
- 生成される画像の品質
- 使用時の注意点やコツ
レビューの数が多いモデルは、多くのユーザーに使用されている証拠となるため、信頼性の高いモデルと言えます。
モデルの使い方と制限
一般的なStable Diffusionモデルの使い方は以下の通りです:
- モデルをダウンロード
- Stable Diffusion Web UIにモデルをインストール
- Web UIでモデルを選択
- プロンプトを入力して画像生成
主な制限事項:
- 商用利用の可否はモデルによって異なる
- 一部のモデルは年齢制限がある
- GPUのVRAM容量によって使用できるモデルサイズに制限がある
おすすめモデルの例
- Anything V5
特徴: 汎用性が高く、多様なスタイルの画像生成が可能 - Realistic Vision V5.1
特徴: 高品質な写実的画像の生成に特化 - DreamShaper
特徴: アニメ風からリアルまで幅広いスタイルに対応
これらのモデルは、多くのユーザーから高い評価を得ており、初心者にもおすすめです。
定期的にランキングやレビューをチェックし、自分の目的に合ったモデルを探すことが重要です。また、モデルの使用には著作権や利用規約に注意を払い、適切に使用することを心がけましょう。
Stable Diffusion aiの記事からの学習と活用方法

Stable Diffusionは、テキストから画像を生成するAIモデルで、特に日本語入力に対応したバージョンも存在します。以下では、Stable Diffusionの基本的な使い方、学習方法、そして初心者向けの登録方法について詳しく解説します。
Stable Diffusionの基本概要
Stable Diffusionは、Stability AIが開発した画像生成AIモデルで、テキストプロンプト(指示文)を入力することで、AIがその内容に基づいた画像を生成します。日本語入力に対応したバージョンもあり、日本文化を理解した高品質な画像生成が可能です[1][2]。
利用方法の比較
Stable Diffusionを利用する方法は大きく分けて以下の3通りがあります:
| 利用方法 | メリット | デメリット |
|---|---|---|
| オンラインサービス | 環境構築不要、クオリティの高い画像生成、無料利用可能 | 機能制限、モデルデータの制約、サーバー混雑時の遅延 |
| クラウドストレージ(Google Colabなど) | 低スペックPCやスマホでも利用可能、前準備が少ない、生成速度が速い | 基本的に有料プランが必要、立ち上げに時間がかかる |
| ローカル環境(自分のPC) | 無料で無制限利用、自由にカスタマイズ可能 | 環境構築が手間、高スペックPCが必要 |
初心者向けの登録と学習方法
登録方法
- オンラインサービスの利用
- Stable Diffusion Onlineなどのウェブサービスにアクセスし、アカウントを作成します。これにより、すぐに画像生成を開始できます。
- クラウドストレージの利用
- Google ColabやPaperspaceにアカウントを作成し、プロジェクトを設定します。Pythonコードを実行することで、Stable Diffusionを利用できます。
- ローカル環境の構築
- 自分のPCにPythonとGitをインストールし、Stable Diffusionのリポジトリをクローンします。必要なモデルデータをダウンロードし、設定を行います。
学習方法
- プロンプトの作成
- 生成したい画像のイメージを具体的にテキストで入力します。例えば、「美しい夕焼けの海岸」などの日本語プロンプトを使用します。
- プロンプトのコツ
- 単語の順番やカンマ(,)の使用など、プロンプトの構成に注意します。ネガティブプロンプトを使用して、不要な要素を排除することも可能です[5][6][9]。
- モデルの選択
- アニメ調やリアル調など、目的に応じて異なるモデルを選択します。Civitaiなどのサイトからモデルデータをダウンロードし、利用することができます[9]。
実際の活用事例
- 広告やプロモーション:アサヒビールやKDDIなどの企業が、Stable Diffusionを利用して広告キャンペーンを展開しています[4]。
- クリエイティブなプロジェクト:Hondaとのコラボレーションで、イベントのビジュアルを生成するなど、多様なクリエイティブプロジェクトに活用されています[4]。
Stable Diffusionは、初心者でも簡単に高品質な画像を生成できる強力なツールです。オンラインサービス、クラウドストレージ、ローカル環境のいずれかを選び、自分に合った方法で利用を開始しましょう。プロンプトの工夫やモデルの選択を通じて、より理想的な画像を生成することが可能です。
以下の表は、利用方法のメリットとデメリットをまとめたものです:
| 利用方法 | メリット | デメリット |
|---|---|---|
| オンラインサービス | 環境構築不要、クオリティの高い画像生成、無料利用可能 | 機能制限、モデルデータの制約、サーバー混雑時の遅延 |
| クラウドストレージ | 低スペックPCやスマホでも利用可能、前準備が少ない、生成速度が速い | 基本的に有料プランが必要、立ち上げに時間がかかる |
| ローカル環境 | 無料で無制限利用、自由にカスタマイズ可能 | 環境構築が手間、高スペックPCが必要 |
自分に合った方法でStable Diffusionを活用し、クリエイティブな画像生成を楽しんでください。





