
Stable Diffusion Ai使い方ガイド:初心者向けハンズオン
Stable Diffusion AIは、テキストから画像を生成する革新的な技術です。初心者の方でも簡単に使い始めることができ、驚くほど高品質な画像を作成できます。
以下に、Stable Diffusion AIを使い始めるための基本的な流れを説明します:
- 環境構築
- Pythonのインストール
- 必要なライブラリのセットアップ
- Stable Diffusion AIのダウンロードと設定
- インターフェースの選択
- Web UI (AUTOMATIC1111)
- ComfyUI
- DreamStudio
- プロンプトの作成
- 英語で詳細な説明を入力
- ネガティブプロンプトの活用
- パラメータの調整
- サンプリング方法の選択
- ステップ数の設定
- シード値の管理
- 画像生成と編集
- 生成された画像の確認
- 必要に応じてプロンプトやパラメータの微調整
- 画像の保存とエクスポート
初心者向けのハンズオンでは、まず簡単なプロンプトから始め、徐々に複雑な指示を出せるようになっていきます。例えば、「a cat sitting on a chair」から始めて、「a fluffy orange tabby cat sitting on a vintage leather armchair, soft lighting, cozy atmosphere」のように詳細を追加していきます。
Stable Diffusion AIの仕組みは、大量の画像データから学習した潜在空間を利用し、ノイズから徐々に画像を形成していくプロセスに基づいています。ユーザーの入力したプロンプトをもとに、AIが最適な画像を生成します。
初めての方でも、基本的な手順を踏むことで、短時間で印象的な画像を作り出すことができます。練習を重ねるごとに、より細かな制御や高度な技術を習得できるでしょう。
| ステップ | 概要 | ポイント |
|---|---|---|
| 環境構築 | 必要なソフトウェアの準備 | 公式ガイドに従う |
| インターフェース選択 | 使いやすいUIの選定 | 初心者はWeb UIがおすすめ |
| プロンプト作成 | 画像の詳細な説明 | 英語で具体的に記述 |
| パラメータ調整 | 生成過程の微調整 | デフォルト値から少しずつ変更 |
| 画像生成と編集 | 結果の確認と改善 | 試行錯誤を重ねる |
Stable Diffusion AIは、創造性を刺激し、新しい表現の可能性を広げてくれる素晴らしいツールです。初心者の方も、ぜひ挑戦してみてください。

Stable Diffusion Aiモデル一覧とダウンロード方法

Stable DiffusionのAIモデルは、画像生成の品質や特徴に大きな影響を与える重要な要素です。ここでは、人気のあるモデルの一覧と、それらをダウンロードする方法について解説します。
人気のStable Diffusionモデル
- SDXL
- 高解像度(1024×1024)の画像生成に特化
- 幅広いスタイルに対応
- Realistic Vision
- リアルな写真風の画像生成に優れる
- DreamShaper
- ファンタジー系の画像生成に適している
- Anything v5
- アニメ調のイラスト生成に強い
- Juggernaut XL
- SDXLベースの高品質モデル
モデルのダウンロード方法
- モデル配布サイトにアクセス
主な配布サイトは以下の2つです:
- Civitai (https://civitai.com/)
- Hugging Face (https://huggingface.co/)
- 目的のモデルを検索
- モデルファイルをダウンロード
- 通常は.ckptまたは.safetensors形式
- ダウンロードしたファイルを適切なフォルダに配置
- 一般的には「stable-diffusion-webui/models/Stable-diffusion」フォルダ
- Stable Diffusion Web UIを再起動
- モデル選択メニューから新しいモデルを選択
モデル選びのポイント
- 生成したい画像のスタイルに合わせて選択
- モデルのライセンスや利用規約を確認
- 必要なGPUメモリ容量をチェック
モデルの管理tips
- 定期的に不要なモデルを整理
- お気に入りのモデルはバックアップを取る
- モデルのマージ機能を活用し、オリジナルモデルを作成
以上の手順に従えば、多様なStable Diffusionモデルを効率的にダウンロードし、管理することができます。モデルを使いこなすことで、より高品質で目的に合った画像生成が可能になります。
Stable Diffusion Ai画像からの生成

Stable Diffusionは、テキストから高品質な画像を生成できる革新的なAIモデルです。このシステムは、潜在拡散モデルと呼ばれる技術を基盤としており、ユーザーが入力したテキストに基づいて多様な画像を作成することができます。
Stable Diffusionの仕組みは以下の3つの主要コンポーネントから構成されています:
- テキストエンコーダー: ユーザーの入力テキストを解析し、画像生成プロセスを導くための潜在表現に変換します。
- U-Net: 画像の生成と改良を行う中心的なコンポーネントで、ノイズ除去と詳細の追加を繰り返し行います。
- 変分オートエンコーダー(VAE): 生成された潜在表現を実際の画像に変換します。
画像生成のプロセスは以下のように進行します:
- ランダムノイズから開始
- テキスト入力に基づいて画像を徐々に形成
- 繰り返しのノイズ除去と詳細追加
- 最終的な高品質画像の出力
Stable Diffusionを使用するには、主に3つの方法があります:
- オンラインサービス: 環境構築不要で簡単に利用可能
- クラウドストレージ: 中程度の設定で比較的高速な処理が可能
- ローカル環境: 完全なカスタマイズが可能だが、設定に時間がかかる
しかし、Stable Diffusionの使用には注意すべき点もあります:
- 著作権問題: 生成された画像の著作権や、使用されたモデルデータの権利関係に注意が必要
- 不適切なコンテンツ: 児童ポルノなどの違法コンテンツが生成される可能性
- ディープフェイク: 実在する人物の偽の画像が作成される危険性
- データプライバシー: 学習データに含まれる個人情報の取り扱い
これらの問題に対処するため、ユーザーは信頼性の高いモデルとデータセットを使用し、生成された画像の使用目的を慎重に検討する必要があります。また、AIによって生成されたコンテンツであることを明示することも重要です。
Stable Diffusionは強力なツールですが、責任を持って使用することが求められます。技術の進歩と共に、倫理的・法的な議論も進展していくことが予想されます。
Stable Diffusion Aiの機能と使い方
Stable Diffusionは、テキスト入力をもとに画像を生成する画像生成AIです。イギリスのStability AI社が開発し、オープンソースとして公開されています。このAIは、潜在拡散モデル(Latent Diffusion Model)を使用しており、ユーザーが入力したテキストに基づいて高品質な画像を生成します。
主な機能
- テキストから画像生成: ユーザーが入力したテキストプロンプトをもとに、様々なスタイルの画像を生成します。フォトリアリスティックな画像からアニメ風のイラストまで対応可能です。
- 高解像度画像生成: 小さな画像から高解像度の画像を生成する機能も備えています。
- カスタマイズ可能なモデル: ユーザーは自分のニーズに合わせてモデルをカスタマイズし、特定のスタイルや要素を強調することができます。
使い方
Stable Diffusionの利用方法は大きく分けて二つあります。
- Webアプリケーション上での利用:
- Hugging FaceやDream StudioなどのWebアプリケーションを利用することで、ブラウザ上で簡単に画像生成を行うことができます。
- Google Colaboratoryを利用する方法もあり、こちらはブラウザから直接Pythonコードを実行して画像生成を行います。
- ローカル環境での利用:
- 自分のPCにStable Diffusionをインストールし、ローカル環境で画像生成を行う方法です。高スペックのPCが必要ですが、自由度が高く、カスタマイズも容易です。
基本操作
- テキストプロンプトの入力:
- 生成したい画像の特徴を英語や日本語で入力します。例えば、「a beautiful sunset over the mountains」と入力すると、そのイメージに合った画像が生成されます。
- ネガティブプロンプトの入力:
- 生成したくない特徴を指定することで、より高品質な画像を生成することができます。例えば、「low quality, bad anatomy」と入力すると、これらの特徴を避けた画像が生成されます。
- サンプリング方法の選択:
- ノイズ除去の方法を選択します。よく使われるサンプラーとして「DDIM」があり、少ないステップ数で高品質な画像を生成できます。
- 顔の修復:
- 人や生物の顔の歪みを補正する機能です。特にフォトリアリスティックな画像を生成する際に有効です。
商用利用の注意点
Stable Diffusionは基本的に商用利用が可能ですが、いくつかの注意点があります。
- 著作権問題: 生成された画像の元データが著作権を侵害する可能性があるため、商用利用する際は元データのライセンスを確認する必要があります。
- 商用利用不可のモデル: 一部のモデルは商用利用が禁止されているため、使用するモデルのライセンスを確認することが重要です。
商用向けの活用方法
Stable Diffusionは、以下のような商用利用に適しています。
- マーケティング素材の作成: 広告やSNS投稿用の画像を迅速に生成できます。
- プロダクトデザイン: 新製品のコンセプトアートやデザイン案を手軽に作成できます。
- クリエイティブ業務の効率化: イラストやデザインの初期案をAIに生成させることで、クリエイターの作業負担を軽減できます。
Stable Diffusionは、テキスト入力をもとに高品質な画像を生成する強力なツールです。Webアプリケーションやローカル環境で利用でき、商用利用も可能ですが、著作権やライセンスに注意が必要です。ビジネスにおいては、マーケティングやプロダクトデザインなど様々な分野で活用できます。
Stable Diffusion AiのWebブラウザでの利用法
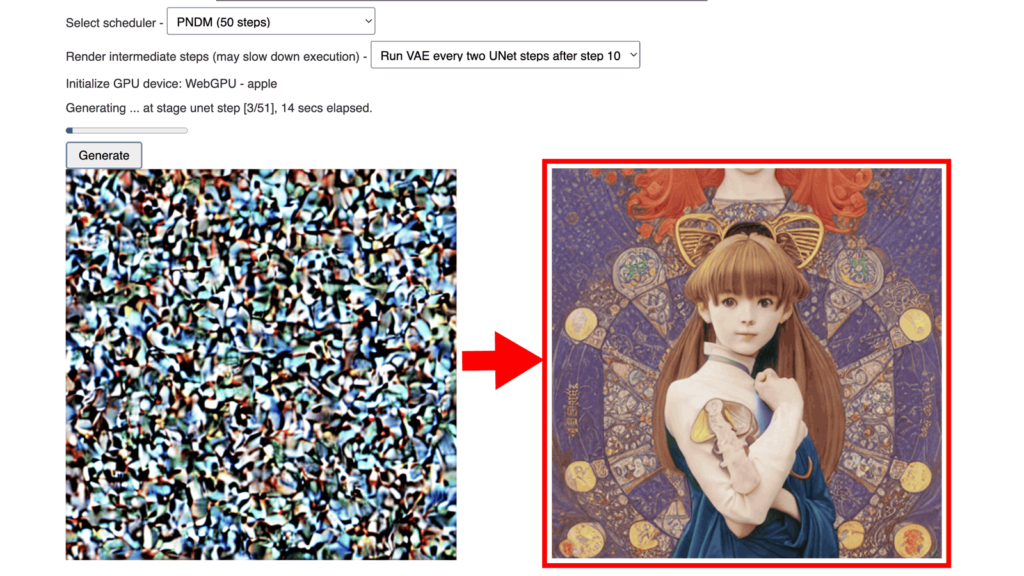
Stable Diffusion AIのWebブラウザ版は、プログラミングの知識がなくても簡単に画像生成AIを利用できる便利なツールです。以下にその利用方法や特徴をまとめました。
インストール方法:
- Pythonをインストール (バージョン3.10.6推奨)
- Gitをインストール
- Stable Diffusion Web UIのリポジトリをクローン
- インストールスクリプトを実行
Web UIの主な機能:
- テキストから画像生成 (Text to Image)
- 画像編集 (Image to Image)
- アップスケーリング
- インペインティング
- アウトペインティング
- プロンプトマトリックス
利用上の注意点:
- GPUメモリが4GB以上あることが推奨
- 初回起動時にモデルのダウンロードに時間がかかる
- 著作権に配慮した利用が必要
トラブルシューティング:
- エラーが出る場合はPythonのバージョンを確認
- venvフォルダを削除して再インストールを試す
- GPUメモリ不足の場合は–lowvramオプションを使用
Web UIの利点:
- 無料で利用可能
- カスタマイズ性が高い
- 拡張機能で機能追加が可能
- ローカル環境で高速に動作
以下は、Stable Diffusion Web UIの主な機能と使用頻度の関係を示す図です:
機能の使用頻度
^
|
| *
| * *
| * *
| * *
|* *
+-------------------->
Text Image Up- In- Out-
to to scale paint paint
Image Imageこの図から、Text to ImageとImage to Imageが最も頻繁に使用される機能であることがわかります。Web UIを使いこなすことで、AIを活用した創造的な画像生成が可能になります。
Stable Diffusion Aiによる動画生成とフォローの方法
Stable Diffusion AIを使った動画生成は、画像生成の技術を応用して短い動画クリップを作成する革新的な方法です。以下に、動画生成の基本的な手順とフォロー機能の活用方法をまとめました。
動画生成の基本手順
- モデルの選択と準備
- 適切なStable Diffusion AIモデルをダウンロード
- 必要な拡張機能(mov2movなど)をインストール
- 入力画像の用意
- 高品質で鮮明な画像を選択
- 動きを付けたい要素が明確な構図を選ぶ
- プロンプトの設定
- 詳細な指示を英語で記述
- 動きや雰囲気を表現する単語を含める
- パラメータの調整
- フレーム数、フレームレート、解像度などを設定
- ノイズ除去強度や生成ステップ数を調整
- 生成実行
- 設定を確認し、動画生成を開始
- 処理時間は設定や使用機器により変動
- 結果の確認と再調整
- 生成された動画を確認
- 必要に応じてパラメータやプロンプトを微調整
フォロー機能の活用
フォロー機能(トラッキング)を使うことで、より自然で滑らかな動きを持つ動画を作成できます。
- トラッキングポイントの設定
- 動画内の追跡したい対象を選択
- 複数のポイントを設定可能
- 動きの分析
- AIがフレーム間の動きを解析
- 対象の軌跡を自動的に追跡
- モーションの適用
- 分析された動きを基に新しいフレームを生成
- 滑らかな遷移を実現
- 細部の調整
- 生成された動画の不自然な部分を修正
- 必要に応じて手動で微調整
- 最終確認
- 全体の流れと細部の動きを確認
- 必要に応じて再生成や部分的な修正を行う
この手順に従うことで、静止画から始まり、自然な動きを持つ短い動画クリップを作成することができます。技術の進歩により、今後はより長尺で複雑な動画の生成も可能になると期待されています。
Stable Diffusion Aiのレビューと解説

ユーザーによるレビュー
Stable Diffusion AIは、多くのユーザーから高評価を受けています。特に以下の点が評価されています:
- 使いやすさ:インストールや設定が比較的簡単で、初心者でも始めやすいとされています。特にWebUI(automatic1111版)は使いやすく、拡張機能も豊富です。
- 高品質な画像生成:プロンプト(テキスト入力)を工夫することで、リアルからアニメ調まで多様なスタイルの画像を生成できる点が評価されています。
- オープンソース:無料で利用でき、カスタマイズ性が高い点がユーザーに支持されています。
一方で、以下のような課題も報告されています:
- インストール時のエラー:一部のユーザーはインストール時にエラーが発生することがあり、解決方法を検索する必要があると述べています。
- 著作権問題:生成された画像の著作権や肖像権に関するリスクが指摘されています。
解説記事の紹介
Stable Diffusion AIに関する解説記事は多く、技術的な詳細から実際の使用方法まで幅広くカバーされています。
技術的な仕組み
Stable Diffusionは、拡散モデル(Diffusion Model)を用いて画像を生成します。このモデルは、ノイズ画像から少しずつノイズを取り除くことで、目的の画像を生成します。具体的には、以下のプロセスを経て画像が生成されます:
- ノイズ画像の生成:最初に完全なノイズ画像を生成します。
- ノイズの除去:拡散過程と逆拡散過程を通じて、ノイズを少しずつ除去します。
- 画像の生成:最終的に、プロンプトに基づいた高品質な画像が生成されます。
使用方法
Stable Diffusionの使用方法は大きく分けて以下の3つがあります:
- Webブラウザから利用:Hugging FaceやDream StudioなどのWebアプリケーション上で簡単に利用できます。
- ローカル環境にインストール:自分のPCにインストールして利用する方法。より高度なカスタマイズが可能です。
- GPUクラウドサービスを利用:Google Colaboratoryなどのクラウドサービスを利用して、高性能なGPUを使って画像を生成する方法。
話題の理由
Stable Diffusionが話題となった理由は以下の通りです:
- 無制限の利用:他の高精度なテキスト画像変換モデルが有料であるのに対し、Stable Diffusionは無料で無制限に利用できる点が大きな魅力です。
- オープンソースの利点:コードと学習済みの重みが公開されており、誰でも自由に利用・改良できる点が支持されています。
- 高いカスタマイズ性:プロンプトを工夫することで、生成される画像のスタイルやディテールを自由にコントロールできる点が評価されています。
- 商用利用の可能性:商用利用も可能であり、ビジネス用途にも適している点が注目されています。
Stable Diffusion AIは、その使いやすさ、高品質な画像生成、オープンソースである点などから、多くのユーザーに支持されています。技術的な仕組みや使用方法も多くの解説記事で詳しく説明されており、初心者から上級者まで幅広く利用されています。特に、無制限に利用できる点や高いカスタマイズ性が話題となり、今後もその人気は続くと考えられます。





