
Stable Diffusion:クリエイティブなビデオ生成の魔法を解き放つ
Stable Video Diffusionの使い方

Stable Video Diffusionは、Stable Diffusionを基にした動画生成AIツールです。画像から動画を生成するための手順を以下に解説します。
基本手順
- 環境の準備
- Google Colabを使用する場合、無料プランでも利用可能ですが、生成に時間がかかることがあります。より快適に利用するためには、有料プランのGPU(例:V100)を推奨します。
- ローカル環境で使用する場合、16GB以上のVRAMを持つGPUが必要です。
- 必要なツールのインストール
- GitHubからStable Video Diffusionのコードをダウンロードし、必要なライブラリをインストールします。
- 画像のアップロード
- 動画の元となる画像をアップロードします。これが動画生成の基となります。
- 設定の調整
- フレーム数: 生成する動画のフレーム数を設定します。一般的には14フレームまたは25フレームが選択可能です。
- ステップ数: 生成時のステップ数を設定します。ステップ数が多いほど、繊細な動画が生成されます。
- 動画生成の実行
- 設定が完了したら、動画生成を実行します。生成には数分かかることがあります。
注意点
- GPUの使用量: 動画生成はGPUリソースを大量に消費します。Google Colabなどのサービスを利用する場合、利用制限に注意が必要です。
- ライセンス: Stable Video Diffusionは非営利目的で無料で利用できますが、商用利用には制限があります。商用利用を希望する場合は、Stability AIのメンバーシップに加入する必要があります。
有名なStable Video Diffusionモデル一覧
Stable Video Diffusionにはいくつかのモデルが公開されています。それぞれのモデルの特徴を以下にまとめます。
| モデル名 | 特徴 | 利用ケース |
|---|---|---|
| stable-video-diffusion-img2vid | 基本的な画像から動画への変換モデル | 一般的な動画生成 |
| stable-video-diffusion-img2vid-xt | 高精度な動画生成が可能 | 高品質な動画生成 |
| stable-video-diffusion-img2vid-xt-1-1 | 軽量で高速なモデル | リソースが限られた環境での利用 |
モデルの選択
- 軽量・高速:
stable-video-diffusion-img2vid-xt-1-1は軽量で高速ですが、生成精度やフレームサイズに制限があります。 - 高精度:
stable-video-diffusion-img2vid-xtは高精度な動画生成が可能で、より繊細な動画を生成したい場合に適しています。
Stable Video Diffusionは、画像から動画を生成する強力なAIツールです。初心者でも簡単に利用できるように設計されており、Google Colabやローカル環境での利用が可能です。モデルの選択や設定を適切に行うことで、高品質な動画を生成することができます。商用利用には制限があるため、利用前にライセンスを確認することが重要です。
Stable Video Diffusionの機能と使いどころ
Stable Video Diffusionは、静止画像を動的な動画に変換するAIツールです。以下のような特徴と機能があります。
主な機能
- 画像から動画生成: 静止画像をもとに、カメラが移動したり、人物が動いたりする短い動画を生成します。
- テキストプロンプトによる動画生成: テキストを入力することで、指定した内容に基づいた動画を生成します。
- カスタマイズ可能なフレームレート: 3から30フレーム/秒のフレームレートで、14または25フレームの動画を生成可能です。
- モデルの選択: 複数のモデルが提供されており、生成精度やフレームサイズに応じて選択できます。
利用方法
- Google Colabでの利用: Google Colabを利用して、GPUを活用した動画生成が可能です。ただし、GPUの利用量に注意が必要です。
- ローカル環境での実行: 高性能なGPUを持つPCでローカルに実行することも可能です。推奨スペックはVRAM 16GB以上です。
Stable Video Diffusionのオススメの機能
1. 画像から動画生成
画像をアップロードするだけで、短い動画を生成できます。特に、カメラの移動や人物の動きをシミュレートする動画を簡単に作成できる点が魅力です。
2. テキストプロンプトによる動画生成
テキストを入力することで、指定した内容に基づいた動画を生成する機能があります。例えば、「夕焼けの海辺で波が打ち寄せるシーン」といった具体的なシーンをテキストで指定できます。
3. カスタマイズ可能なフレームレート
生成する動画のフレームレートを3から30フレーム/秒の範囲でカスタマイズできます。これにより、用途に応じた滑らかな動画を生成することが可能です。
Stable Video Diffusionのユーザーセキュリティについて
セキュリティ対策
- オンプレミス運用: ローカル環境での実行が可能なため、データのプライバシーを保護しやすいです。外部にデータを送信する必要がないため、機密情報の漏洩リスクが低減されます。
- 著作権と個人情報の保護: 入力画像の著作権や個人情報に注意が必要です。特に、商用利用を考える場合は、著作権侵害のリスクを避けるために、使用する画像の権利を確認することが重要です。
- ニューラルネットワークによる漏洩リスク: 学習データセットから元の画像を再現する可能性があるため、意図しない個人情報の漏洩リスクがあります。この点については、モデルの使用時に十分な注意が必要です。
現段階での利用制限
Stable Video Diffusionは現在、研究用途に限定されており、商用利用は制限されています。安全性と品質向上のためのフィードバックを求めている段階です。
Stable Video Diffusionは、静止画像から動的な動画を生成する革新的なAIツールです。カスタマイズ可能なフレームレートやテキストプロンプトによる動画生成など、多様な機能を提供しています。一方で、ユーザーセキュリティの観点からは、オンプレミス運用や著作権・個人情報の保護に注意が必要です。現段階では研究用途に限定されているため、商用利用を考える場合は今後のアップデートに注目する必要があります。
Stable Video Diffusionの画像から動画について
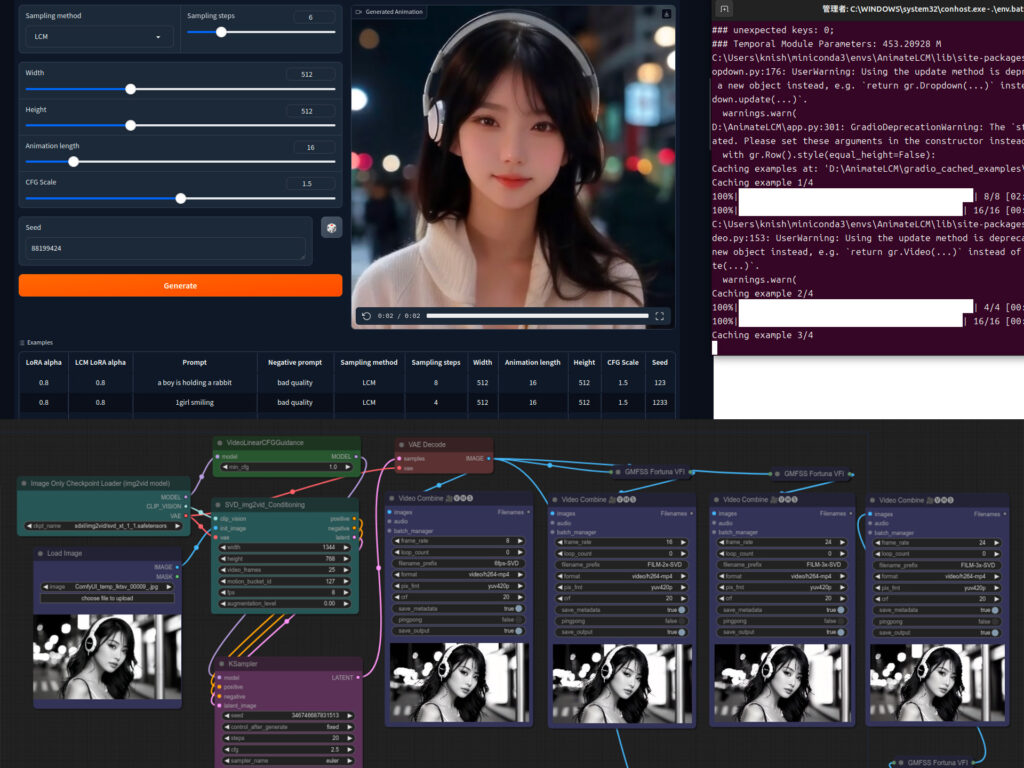
Stable Video Diffusionは、静止画から動画を生成する革新的なAI技術として注目を集めています。この技術を活用することで、クリエイターや企業は簡単に魅力的な動画コンテンツを作成できるようになりました。
Stable Video Diffusionの主な特徴と魅力は以下の通りです:
- 簡単な操作性
単一の静止画像をアップロードするだけで、数分以内に動画を生成できます。専門的な知識や複雑な編集スキルは必要ありません。 - 高品質な出力
生成される動画は、最大30FPSのフレームレートで滑らかな動きを実現。14フレームまたは25フレームのオプションがあり、用途に応じて選択できます。 - カスタマイズ性
カメラモーションやシード値などのパラメータを調整することで、生成される動画の雰囲気や動きを制御できます。 - 幅広い応用可能性
広告、教育コンテンツ、エンターテインメント、ソーシャルメディア投稿など、様々な分野で活用できます。 - 時間と労力の節約
従来の動画制作と比較して、大幅な時間短縮とコスト削減が可能です。 - クリエイティビティの拡張
静止画では表現しきれなかったアイデアを動画として具現化できるため、クリエイターの表現の幅が広がります。
Stable Video Diffusionを活用することで、以下のようなメリットが得られます:
- マーケティング効果の向上: 動く広告や商品紹介動画で顧客の注目を集める
- 教育コンテンツの充実: 複雑な概念を動きのある映像で分かりやすく説明
- SNSでの拡散力アップ: 目を引く動画投稿でエンゲージメント率を向上
- アート作品の新たな表現: 静止画アートに動きを加えて新しい体験を創出
ただし、現時点では生成できる動画の長さに制限があり、細かい動きの制御にも限界があります。また、著作権や肖像権の問題にも注意が必要です。
今後の技術発展により、より長尺で高品質な動画生成が可能になると期待されています。Stable Video Diffusionは、動画制作の民主化と創造性の解放に大きく貢献する可能性を秘めた魅力的な技術だと言えるでしょう。
Stable Video Diffusionの動画生成におけるコントロール
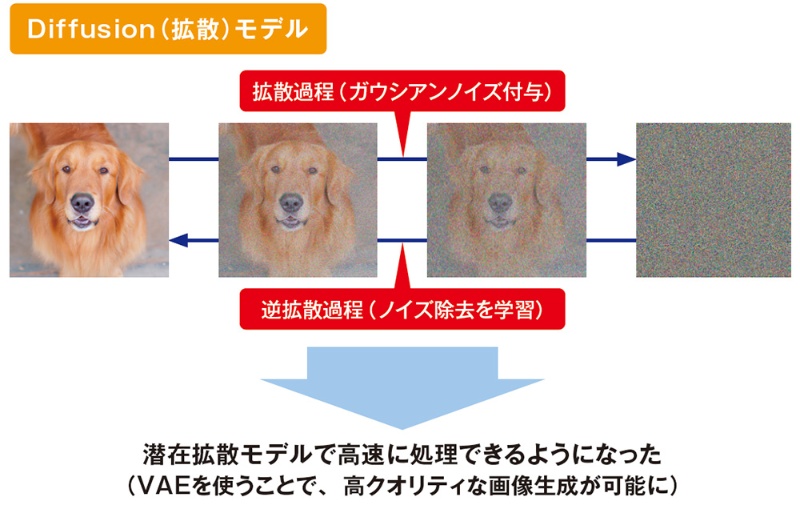
Stable Video Diffusionは、画像から動画を生成する革新的なAI技術です。この技術は、Stable Diffusionの画像生成モデルを基盤としており、動画制作の概念を大きく変えつつあります。
動画生成の仕組み
Stable Video Diffusionの動画生成プロセスは、以下のように機能します:
- ランダムなノイズから開始
- 徐々にノイズを除去
- フレーム間の時間的つながりを維持
特筆すべき点は、空間畳み込みの後に時間畳み込みを行う独自のアーキテクチャです。これにより、フレーム間の一貫性が保たれ、違和感のない動画が生成されます。
生成のコントロール
動画生成をコントロールするための主要なオプションには以下があります:
- フレーム数:生成する動画のフレーム数を設定
- ステップ数:生成プロセスの詳細度を調整(高いほど繊細な動画に)
また、3つの主要なモデルが公開されています:
- stable-video-diffusion-img2vid
- stable-video-diffusion-img2vid-xt
- stable-video-diffusion-img2vid-xt-1-1
これらは生成精度とフレームサイズの上限が異なるため、目的に応じて選択することが重要です。
必要なスペックと注意点
Stable Video Diffusionを効果的に利用するには、高性能なハードウェアが必要です:
- 高性能GPU
- 十分なメモリ
- 高速プロセッサ
特に注意すべき点として、動画生成はGPUを大量に消費するため、利用制限のあるサービス(Google Colabなど)では注意が必要です。
料金体系
Stable Video Diffusionの料金体系は以下のようになっています:
- 基本的な使用:無料(非商業的・研究目的に限定)
- 商用利用:有料(具体的な料金は提供元により異なる)
活用事例
Stable Video Diffusionは様々な分野で活用されています:
- 映画制作
- 医療分野
- 自動車産業
これらの分野では、時間とコストを節約しながら創造的なビジョンを実現するツールとして機能しています。
Stable Video Diffusionは、AI技術を用いた動画生成の最前線にあるツールです。適切なハードウェア、モデル選択、そして生成オプションの調整により、高品質な動画コンテンツを効率的に作成することが可能です。ただし、商用利用の際には料金体系や利用規約を十分に確認することが重要です。
Google向けStable Video Diffusionの動画生成手順

Google Colabを活用したStable Video Diffusionによる動画生成の手順を解説します。この方法を使えば、高品質な動画を簡単に作成できます。
セットアップ
- Google Colabを開き、新しいノートブックを作成します。
- ランタイムタイプをGPUに設定します。T4以上のGPUを推奨します。
- 必要なライブラリをインストールします:
!pip install torch torchvision torchaudio
!pip install transformers diffusers accelerate
!pip install opencv-python moviepy- Hugging FaceのAPIトークンを設定します:
import os
os.environ["HUGGINGFACE_TOKEN"] = "your_token_here"モデルのロード
Stable Video Diffusionモデルをロードします:
from diffusers import StableVideoDiffusionPipeline
import torch
pipe = StableVideoDiffusionPipeline.from_pretrained(
"stabilityai/stable-video-diffusion-img2vid-xt",
torch_dtype=torch.float16,
variant="fp16"
)
pipe = pipe.to("cuda")動画生成
- 入力画像をアップロードします:
from google.colab import files
uploaded = files.upload()
image_path = list(uploaded.keys())[0]- 動画を生成します:
import PIL.Image
image = PIL.Image.open(image_path)
generator = torch.Generator(device="cuda").manual_seed(42)
frames = pipe(image, num_frames=25, generator=generator).frames- 生成された動画を保存します:
import cv2
import numpy as np
output_path = "output_video.mp4"
fps = 7
height, width, layers = frames[0].shape
video = cv2.VideoWriter(output_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (width, height))
for frame in frames:
video.write(cv2.cvtColor(np.array(frame), cv2.COLOR_RGB2BGR))
video.release()- 生成された動画をダウンロードします:
from google.colab import files
files.download(output_path)最適化のヒント
- 高品質な結果を得るには、入力画像の解像度を1024×576にリサイズすることをおすすめします。
- num_framesパラメータを調整して、生成する動画の長さを制御できます。
- generatorのseed値を変更することで、異なるバリエーションの動画を生成できます。
注意点
- Google Colabの無料版では、GPUの使用時間に制限があります。長時間の使用や大量の動画生成には有料版の利用を検討してください。
- 生成された動画の品質は入力画像に大きく依存します。鮮明で高解像度の画像を使用すると、より良い結果が得られます。
- モデルのダウンロードと初期化に時間がかかる場合があります。特に初回実行時は待機時間が長くなることがあります。
この手順に従えば、Google ColabとStable Video Diffusionを使って、簡単に高品質な動画を生成できます。実験を重ねて、最適なパラメータを見つけてください。
Stable Video Diffusionアプリを使った動画生成

Stable Video Diffusionは、画像やテキストから短い動画を生成できる革新的なAI技術です。このアプリを使うことで、クリエイターや一般ユーザーが手軽に高品質な動画コンテンツを作成できるようになりました。
Stable Video Diffusionの主な魅力は以下の点にあります:
- 簡単な操作で短時間に動画を生成できる
- 静止画に動きを加えることができる
- テキストプロンプトから動画を作成できる
- 高品質な結果が得られる
アプリを使って動画を生成するための基本的なステップは次のとおりです:
- アプリをインストールし、アカウントを作成する
- 画像をアップロードするか、テキストプロンプトを入力する
- 動画の長さやフレームレートなどの設定を調整する
- 「生成」ボタンをクリックして動画を作成する
- 結果を確認し、必要に応じて設定を変更して再生成する
- 完成した動画をダウンロードする
以下は、Stable Video Diffusionで生成できる動画の種類と用途をまとめた表です:
| 入力 | 出力 | 主な用途 |
|---|---|---|
| 静止画 | アニメーション | SNS投稿、プレゼン資料 |
| テキスト | 短編動画 | 広告、教育コンテンツ |
| 複数画像 | スライドショー | 思い出ビデオ、プロモーション |
Stable Video Diffusionは直感的なインターフェースを備えているため、プロのクリエイターでなくても簡単に使いこなすことができます。ただし、より良い結果を得るためには、適切なプロンプトの書き方や設定の調整など、いくつかのコツを押さえる必要があります。
また、生成された動画の品質は入力する画像やプロンプトの質に大きく依存します。そのため、クリアな画像や具体的なプロンプトを用意することで、よりクオリティの高い動画を作成できます。
Stable Video Diffusionは日々進化を続けており、今後はより長尺の動画生成や、さらに高度な編集機能の追加なども期待されています。クリエイティブな表現の可能性を大きく広げるこの技術は、動画制作の世界に革命をもたらす可能性を秘めています。





