
画像生成 AI の過去、現在、未来
Stable Diffusion画像生成AI の歴史と未来

Stable Diffusion画像生成AIの歴史と未来、その特徴、ダウンロード方法、注目モデルについて包括的に解説します。
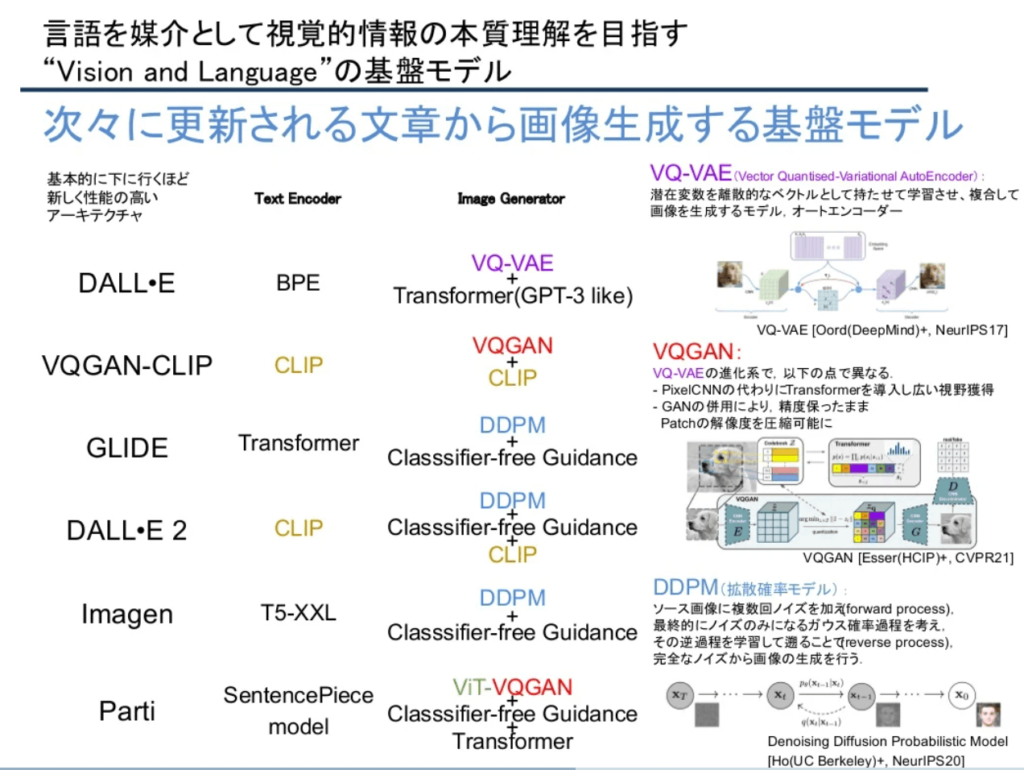
画像生成AIの進化
画像生成AI技術は2014年のGAN(敵対的生成ネットワーク)の登場を契機に急速な発展を遂げました。その後、OpenAIのDALL-E 2やMidjourneyなど、次々と革新的な技術が登場しました。2022年に公開されたStable Diffusionは、高品質な画像生成を可能にし、オープンソースという特徴から大きな注目を集めました。
Stable Diffusionの特徴
Stable Diffusionは潜在拡散モデルを基盤とし、テキストプロンプトから画像を生成する能力を持ちます。既存画像の編集や部分的な変更も可能で、多様な用途に対応します。特筆すべきは、比較的少ないVRAMでも動作可能な点です。
ダウンロードと使用方法
Stable Diffusion Web UI(AUTOMATIC1111)は、ブラウザベースで簡単に利用できるインターフェースです。以下に基本的なセットアップ手順を示します:
- 必要なソフトウェアのインストール(Git、Python等)
- リポジトリのクローン
- 依存関係のインストール
- Web UIの起動
注目モデル
Stable Diffusionの人気モデルは、実写・リアル系とアニメ・イラスト系に大別されます。
実写・リアル系トップ3:
- Yayoi_mix
- BRA V6
- CityEdgeMix
アニメ・イラスト系トップ3:
- Anime Pastel Dream
- anything v5
- MeinaUnreal
これらのモデルは、それぞれ独自の特徴や強みを持ち、用途に応じて選択できます。
未来展望
Stable Diffusionを含む画像生成AI技術は急速に進化しており、今後はより高品質で多様な画像生成が可能になると予想されます。また、動画生成や3Dモデル生成など、新たな領域への拡張も期待されています。
一方で、著作権問題やディープフェイクなどの倫理的課題も浮上しており、技術の発展と並行してこれらの問題への対応も重要になってくるでしょう。
Stable Diffusionは、クリエイティブな表現の新たな可能性を開く一方で、責任ある使用が求められる技術です。今後の発展と社会への影響に注目が集まっています。
Stable Diffusion AI の過去から学ぶ
Stable Diffusion AI の概要
Stable Diffusionは、テキストから画像を生成するAIモデルであり、Stability AIが開発しました。このモデルは、潜在拡散モデル(Latent Diffusion Model)を使用しており、ユーザーが入力したテキストプロンプトに基づいて高品質な画像を生成します。オープンソースとして公開されているため、誰でも無料で利用できる点が特徴です。
Stable Diffusion AI の歴史
Stable Diffusionは2022年8月に初めて公開されました。公開当初からオープンソースとして提供されており、誰でも自由にモデルを学習・改良できる環境が整っています。2023年にはStable Diffusion XLなどの新バージョンがリリースされ、モデルの性能や表現力がさらに向上しました。
Stable Diffusion AI の動画解説
Stable Diffusionを使った動画生成の方法については、YouTubeに多くの解説動画があります。例えば、Deforum機能を使ってアニメーション動画を作成する方法が紹介されています。Deforumをインストールし、プロンプトを入力することで、滑らかなアニメーションを生成できます。
Stable Diffusion AI のカスタムモデルの構築方法
Stable Diffusionでカスタムモデルを構築する方法は以下の通りです:
- 環境の準備:
- Google Colabを開き、GitHubから必要なノートブックをインポートします。
- 必要なライブラリやモデルをインストールします。
- モデルの選択とマージ:
- Civitaiなどのプラットフォームから、マージしたいモデルを2つまたは3つ選びます。
- 選んだモデルをStable Diffusionに導入し、マージします。マージの比率や補完方法を設定することで、オリジナルのカスタムモデルを作成できます[10][14]。
- LoRAやEmbeddingの利用:
- LoRA(Latent space Of Rendered Animations)やEmbeddingファイルを使用することで、特定の要素を強調したり、テキスト情報を数値に変換して意図を明確に伝えることができます。これにより、カスタムモデルの表現力をさらに高めることができます。
カスタムモデル構築の手順
| 手順 | 説明 |
|---|---|
| 1. 環境の準備 | Google Colabを開き、必要なノートブックをインポート |
| 2. モデルの選択 | Civitaiなどからモデルを選び、導入 |
| 3. モデルのマージ | 選んだモデルをマージし、比率や補完方法を設定 |
| 4. LoRAの利用 | LoRAファイルを導入し、特定の要素を強調 |
| 5. Embeddingの利用 | Embeddingファイルを使用して意図を明確に伝える |
Stable Diffusionは、オープンソースであり、カスタムモデルの構築が比較的容易であるため、多くのクリエイターに利用されています。これにより、ユーザーは自分のニーズに合わせた独自の画像生成モデルを作成することができます。
Stable Diffusion AI の未来と可能性

Stable Diffusionは、Stability AI社が開発した画像生成AIで、テキストプロンプトを入力するだけで高品質な画像を生成することができます。この技術は、クリエイティブな作業を大幅に効率化し、デザインやアートの分野に革命をもたらす可能性があります。
未来の展望
Stable Diffusionの未来には以下のような可能性が考えられます。
- クリエイティブ産業の変革: デザイナーやアーティストがアイデアを迅速にビジュアル化できるため、制作プロセスが効率化されます。
- 教育とトレーニング: 教育現場でのビジュアル教材の作成や、トレーニングプログラムでのシミュレーションに利用される可能性があります。
- エンターテインメント業界: 映画やゲームの制作において、背景やキャラクターのデザインを迅速に行うことができ、制作コストと時間を削減できます。
- マーケティングと広告: 広告キャンペーンのビジュアルコンテンツを迅速かつ効果的に作成するためのツールとして利用されます。
Stable Diffusion XL とは
Stable Diffusion XL(SDXL)は、Stable Diffusionの最新モデルで、以前のバージョンよりも高精度で多様なスタイルの画像を生成することができます。SDXLは、2023年7月に正式版がリリースされ、その後11月にSDXL Turboが発表されました。
特徴
- パラメータ数の増加: 基本モデルは3.5B(35億)のパラメータを持ち、リファイメントモデルは6.6B(66億)のパラメータを持ちます。
- 画像生成プロセスの改善: 2段階の生成プロセスにより、まず基本モデルが画像の草案を生成し、その後リファイメントモデルが画像を精密化します。
- デフォルトの画像生成サイズの拡大: より大きな画像を生成することが可能です。
Stable Diffusion Webブラウザアプリを使った画像生成の基本
Stable DiffusionをWebブラウザで利用する方法は、初心者にも簡単で手軽に始められるため人気があります。以下に基本的な手順を示します。
手順
- Webアプリケーションにアクセス: Hugging FaceやDream StudioなどのWebアプリケーションにアクセスします。
- アカウント作成とログイン: 必要に応じてアカウントを作成し、ログインします。
- プロンプトの入力: 生成したい画像のイメージをテキストプロンプトとして入力します。例えば、「sunset over a mountain range」など。
- 生成オプションの設定: 必要に応じて、画像の解像度やスタイルなどのオプションを設定します。
- 画像生成の実行: 「生成」ボタンをクリックして画像を生成します。
- 結果の確認とダウンロード: 生成された画像を確認し、気に入ったものをダウンロードします。
メリットとデメリット
| メリット | デメリット |
|---|---|
| 簡単に始められる | 生成枚数に制限がある場合がある |
| 高性能なPCが不要 | 一部機能が有料 |
Stable Diffusionは、クリエイティブな作業を効率化し、多くの分野での応用が期待される強力なツールです。特に最新モデルのSDXLは、より高品質な画像生成を可能にし、今後の展開が非常に楽しみです。Webブラウザアプリを利用することで、誰でも簡単にこの技術を体験することができます。
Stable DiffusionのWebアプリケーションと応用
Stable DiffusionのWebアプリケーションは、ブラウザ上で手軽に画像生成AIを利用できる便利なツールです。主な特徴と機能を以下にまとめました:
基本的な使い方
- テキストプロンプトを入力
- 画像サイズや生成数を設定
- 「Generate」ボタンをクリック
- AIが画像を生成
便利な機能
- img2img: 既存の画像を元に新しい画像を生成
- インペインティング: 画像の一部を選択して修正
- アップスケーリング: 低解像度の画像を高解像度化
- LoRA: 少量のデータで特定のスタイルを学習
拡張機能
Webアプリの機能を拡張できるプラグインが多数あります:
- ControlNet: ポーズや構図を指定して生成
- Infinite Zoom: ズームイン/アウトするアニメーション生成
- Deforum: 短い動画の生成
セキュリティと問題解決
- ローカル環境での使用を推奨(データ流出防止)
- エラー発生時はドライバーの更新やキャッシュクリアを試す
- 公式フォーラムやGitHubで最新の情報を確認
Stable Diffusion Webアプリは、直感的なUIと豊富な機能で、プログラミング知識がなくても高度な画像生成が可能です。拡張機能を活用することで、さらに表現の幅を広げられます。セキュリティに注意しながら使用すれば、クリエイティブな作業の強力な味方となるでしょう。
Stable Diffusion AI と画像生成の未来
Stable Diffusion AIは画像生成技術の革新をもたらし、その進化は今後も加速していくと考えられます。
最新のStable Diffusion 3では、画像内のテキスト生成精度が大幅に向上し、バナーやクリエイティブ画像の作成がより簡単になりました。また、人体の描写や構図の安定性も改善されており、より自然で高品質な画像生成が可能になっています。
今後の展望としては、以下のような方向性が考えられます:
- モデルの軽量化と高速化
より小さなモデルサイズで高品質な画像生成を実現し、モバイルデバイスなどでもスムーズに動作するようになると予想されます。 - マルチモーダル生成の進化
テキストだけでなく、音声や動画など複数のモダリティを組み合わせた生成が可能になり、より豊かな表現が実現できるでしょう。 - ユーザーインターフェースの改善
プロンプトエンジニアリングの知識がなくても、直感的な操作で望みの画像を生成できるUIの開発が進むと考えられます。 - 倫理的・法的課題への対応
著作権問題や偽情報生成などの課題に対して、適切な制御や規制の仕組みが整備されていくでしょう。 - 産業応用の拡大
広告、エンターテインメント、製品デザインなど、様々な分野での実用的な活用が広がると予想されます。
これらの進化により、Stable Diffusion AIは単なる画像生成ツールから、クリエイティブワークを支援する強力なパートナーへと進化していくことが期待されます。
以下は、Stable Diffusion AIの性能向上の推移を示す概念図です:
性能
^
| *
| *
| *
| *
| *
+--------------------------->
v1 v2 v3 v4 v5 バージョンこの図は、各バージョンアップで画質や機能が飛躍的に向上していることを示しています。今後もこの急激な進化が続くと予想されます。

Stable Diffusionの実用的な運用例と事例
Stable Diffusionは、テキストから画像を生成する高性能なAIモデルであり、さまざまなビジネスシーンで活用されています。以下に、具体的な運用例と成功事例を紹介します。
実用的な運用例
オリジナルグッズの作成
Stable Diffusionを使用して生成した画像を利用し、オリジナルグッズを作成することができます。例えば、Tシャツ、スマホケース、カップなどに画像を印刷して販売することが可能です。これにより、独自のデザインを持つ商品を手軽に作成できます。
プレゼン資料の挿絵
プレゼンテーションの資料に適したオリジナルの挿絵を生成することができます。これにより、プレゼン資料のビジュアルを強化し、視覚的なインパクトを与えることができます。
ビジネスでの活用事例
Hondaとのコラボレーション
2023年のJAPAN MOBILITY SHOWで、HondaはStable Diffusionを活用した注目の企画を展開しました。これにより、ブランドのイメージ向上と技術力のアピールに成功しました。
TOKYO MXのイメージCM
TOKYO MXは、イメージCM『TOKYO MX どこまでも!マニアッ9。』篇の制作にStable Diffusionを利用しました。これにより、独自性のある映像表現を実現し、視聴者の関心を引きました。
KDDIの年始CM
KDDIは、画像生成AIを用いて「三太郎シリーズ」の年始CMをアニメーションにリメイクしました。これにより、視聴者に新鮮な印象を与え、ブランドの魅力を高めました。
アサヒビールのプロモーション
アサヒビールは、画像生成AIを体験型プロモーションに活用しました。具体的には、「アサヒスーパードライ ドライクリスタル」のブランドサイト内で、ユーザーが生成した画像を楽しむことができるコンテンツを提供しました。
成功事例
オリジナルグッズの販売
Stable Diffusionを活用して生成した画像を用いたオリジナルグッズの販売は、多くの企業や個人にとって成功事例となっています。例えば、特定のテーマに基づいたデザインのTシャツやスマホケースが人気を集めています。
プレゼン資料の改善
プレゼンテーション資料にオリジナルの挿絵を追加することで、視覚的な魅力が増し、プレゼンの効果が向上した事例があります。これにより、ビジネスミーティングやセミナーでの評価が高まりました。
画像生成サービスへの応用
Stable Diffusionは、画像生成サービスとしても広く応用されています。例えば、ユーザーが入力したテキストに基づいて、独自の画像を生成するオンラインサービスが提供されています。これにより、クリエイティブなコンテンツ制作が容易になり、多くのユーザーに利用されています。
Stable Diffusionの活用例
上記の図は、Stable Diffusionを活用したオリジナルグッズの一例です。このように、生成された画像を多様な製品に応用することが可能です。
Stable Diffusionは、ビジネスの多様なニーズに応える強力なツールであり、今後もさらなる活用が期待されます。





