
Stable Diffusion AIが未来の想像力を実現する
Stable Diffusion aiの使い方と注目の機能を解説

Stable Diffusion AIは、テキストプロンプトから高品質な画像を生成できる強力な画像生成AIツールです。その使い方と注目の機能、商用利用の可能性、そしてセキュリティ上の懸念点について解説します。
主な特徴と使い方
Stable Diffusionは、テキストプロンプトを入力するだけで驚くほど高品質な画像を生成できます。主な特徴は以下の通りです:
- オープンソースで無料利用可能
- 多様なスタイルの画像生成が可能
- ウェブブラウザ版とローカルインストール版がある
- 商用利用も条件付きで可能
使い方は非常にシンプルで、以下の手順で画像を生成できます:
- プロンプトを入力
- 画像サイズやその他パラメータを設定
- 「Generate」ボタンをクリック
- 数秒〜数十秒で画像が生成される
注目の機能
img2img
既存の画像をベースに新しい画像を生成する機能です。元画像のスタイルや構図を維持しながら、新しい要素を追加したり変更したりできます。
インペインティング
画像の一部を選択して、その部分だけを再生成する機能です。背景の一部を変更したり、不要な要素を削除したりするのに便利です。
アップスケーリング
低解像度の画像を高解像度に変換する機能です。AIが細部を補完するため、単純な拡大よりも高品質な結果が得られます。
商用利用の可能性
Stable Diffusionは基本的に商用利用が可能ですが、以下の点に注意が必要です:
- 生成された画像の著作権はユーザーに帰属
- 一部のモデルやデータセットには商用利用の制限がある場合がある
- 有名人や商標などを含む画像の商用利用には注意が必要
広告、書籍の挿絵、ウェブサイトのデザイン素材など、様々な用途での活用が期待できます。ただし、具体的な利用方法については、最新のライセンス条項を確認することをお勧めします。
セキュリティ上の懸念点
Stable Diffusionを含む生成AIには、いくつかのセキュリティリスクが指摘されています:
- 情報漏洩のリスク
入力したプロンプトや画像に機密情報が含まれていると、それが学習データに取り込まれる可能性があります。 - バックドア攻撃の脆弱性
悪意のある攻撃者が学習モデルにバックドアを仕掛け、特定のトリガーで望まない画像を生成させる可能性があります。 - 著作権侵害のリスク
学習データに著作権で保護された画像が含まれている可能性があり、生成された画像が意図せず著作権を侵害する可能性があります。
これらのリスクを軽減するために、以下の対策が推奨されます:
- 機密情報を含むプロンプトや画像の使用を避ける
- 信頼できるソースからモデルをダウンロードする
- 生成された画像の著作権チェックを行う
- 企業での利用時はセキュリティポリシーを策定する
Stable Diffusion AIは、その高い画質と柔軟性から、クリエイティブ業界に革命をもたらす可能性を秘めています。商用利用の可能性も高く、様々なビジネスシーンでの活用が期待できます。一方で、セキュリティや著作権の問題には十分な注意が必要です。これらのリスクを理解し、適切に管理することで、Stable Diffusion AIの恩恵を最大限に活かすことができるでしょう。
技術の進歩とともに、これらの課題に対する解決策も日々進化しています。Stable Diffusion AIの利用を検討する際は、最新の情報を常にチェックし、適切な判断を行うことが重要です。
Stable Diffusion aiの画像生成AIとしての仕組みと機能を活用するための情報
Stable Diffusionは、テキストから高品質な画像を生成できる革新的な画像生成AIモデルです。その仕組みと機能を理解し、効果的に活用するためには以下のポイントが重要です:
仕組みと主な機能
Stable Diffusionは潜在拡散モデルと呼ばれるアルゴリズムを使用しています。このモデルは、ノイズから徐々に画像を生成していく過程で、入力されたテキストの意味を反映させながら画像を作り上げます。
主な機能としては:
- テキストから画像生成
- 既存画像の編集・加工
- 画像の高解像度化
- 動画生成
活用のためのポイント
適切なプロンプト設計
生成される画像の品質は入力するプロンプト(テキスト)に大きく依存します。効果的なプロンプトを作成するコツとしては:
- 具体的な描写を含める
- スタイルや雰囲気を指定する
- ネガティブプロンプトも活用する
モデルの選択
目的に応じて適切なモデルを選ぶことが重要です。一般的な用途には汎用モデルが適していますが、特定のスタイルを求める場合は専用のファインチューニングモデルを使用するとよいでしょう。
画像のスペック
Stable Diffusionで生成される画像は通常512×512ピクセルですが、高解像度化機能を使うことで最大4096×4096ピクセルまで拡大できます。画質は使用するモデルやパラメータ設定によって変わりますが、適切に設定すれば商用利用可能な高品質な画像を生成できます。
環境構築とインストール
Stable Diffusionを簡単に使い始めるには、以下の手順で環境を整えます:
- 必要なソフトウェアのインストール
- Python 3.10以上
- Git
- Visual C++ Redistributable
- Stable Diffusion Web UIのダウンロード
GitHubからリポジトリをクローン - 必要なモデルファイルのダウンロード
Hugging Faceなどから入手 - 起動スクリプトの実行
webui-user.batを実行してWeb UIを起動 - ブラウザでアクセス
通常はhttp://localhost:7860にアクセス
応用例
Stable Diffusionの活用例としては:
- イラスト制作の補助ツール
- 製品デザインのアイデア出し
- 映像制作の背景画像生成
- ウェブサイトやアプリのUI素材作成
このように、Stable Diffusionは創造的な作業を大幅に効率化し、新しい表現の可能性を広げるツールとして注目されています。適切な環境設定と使い方を身につけることで、様々な分野での活用が期待できます。
Stable Diffusion aiの専用モデルや完成度に関わる情報
Stable Diffusion AIは、画像生成の分野で注目を集めている強力なツールです。日本のユーザーにとって特に興味深い点がいくつかあります。
まず、Stable Diffusion AIには日本語に特化したモデルが存在します。「Japanese Stable Diffusion XL (JSDXL)」と呼ばれるこのモデルは、日本語入力に対応しているだけでなく、日本の文化や伝統を反映した画像生成が可能です。これにより、日本市場向けのデザインや広告制作など、幅広い用途に活用できます。
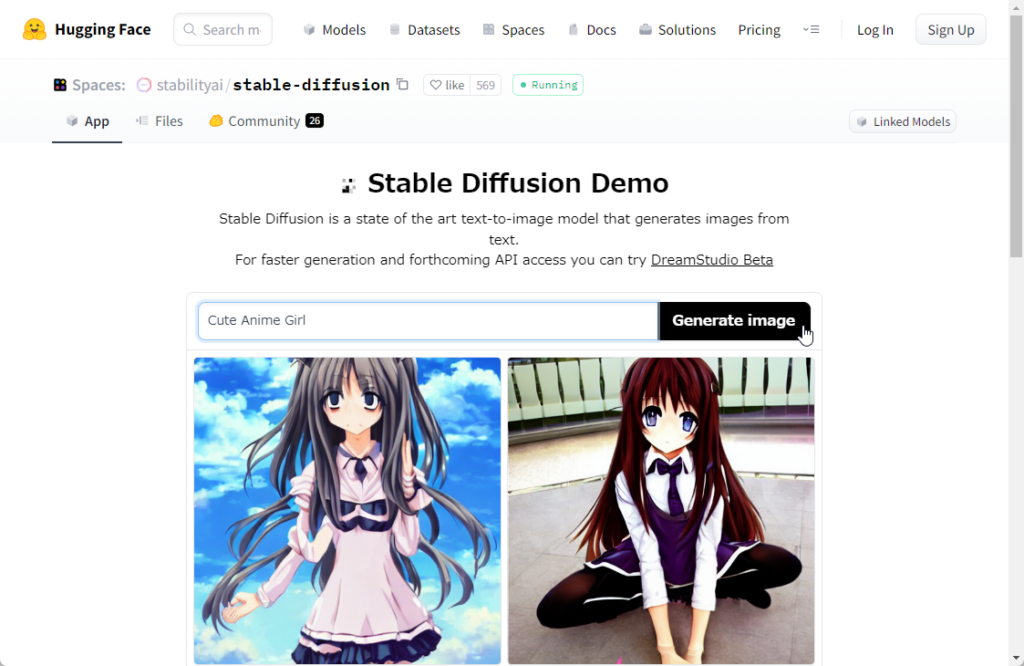
Stable Diffusion AIの使用方法としては、Hugging FaceやDream Studioなどのプラットフォームがあります。Hugging Faceでは、コミュニティベースでモデルの改善が行われており、常に進化し続けています。Dream Studioは、より迅速な画像生成が可能で、初心者にも使いやすいインターフェースを提供しています。
日本語対応に関しては、Stable Diffusion WebUIを日本語化する方法があります。これは拡張機能をインストールすることで簡単に実現できます。具体的な手順は以下の通りです:
- WebUI内の「Extensions」を開く
- 「Available」タブで「localization」のチェックを外す
- 「ja_JP Localization」をインストール
- 設定を適用し、UIをリロード
この日本語化により、専門用語が多いWebUIの操作が格段に容易になります。
Stable Diffusion AIの完成度を高めるためには、プロンプト(呪文)の使い方が重要です。効果的なプロンプトの例として:
- 詳細な描写:「高解像度の、細部まで描き込まれた日本庭園」
- スタイル指定:「葛飾北斎風の富士山」
- 強調構文:「((和装))の女性、伝統的な日本家屋」
これらのテクニックを駆使することで、より精密で目的に合った画像生成が可能になります。
Stable Diffusion AIは日々進化を続けており、特に日本語対応や日本文化への理解を深めています。これにより、日本のクリエイターやビジネス関係者にとって、ますます有用なツールとなっています。
Stable Diffusion aiの専門家によるアドバイスとWebアプリケーションに関する裏話
Stable Diffusionに関する専門家の見解と最新動向
Stable Diffusionは画像生成AIの分野で急速に進化を遂げており、その影響力は拡大し続けています。専門家によると、今後数年でさらなる飛躍的な進歩が見込まれるとのことです。
最新のStable Diffusion 3では、テキストの正確な反映や文字生成の精度が大幅に向上しました。これにより、ロゴデザインやブランディングにおける活用の幅が広がっています。また、エッジコンピューティングの発展に伴い、スマートフォンなどのデバイス上でもリアルタイムに高品質な画像生成が可能になると予測されています。
ビジネスにおける活用事例も増加しており、広告制作やプロダクトデザイン、コンセプト開発など幅広い分野で導入が進んでいます。特に、アイデア出しの初期段階でStable Diffusionを活用することで、クリエイティブプロセスの効率化と質の向上が実現できるとされています。
一方で、著作権や倫理的な問題も指摘されており、AIが生成した画像の取り扱いには注意が必要です。専門家は、適切なガイドラインの整備と、人間の創造性とAIの融合が重要だと強調しています。
Stable Diffusionの活用Q&A
Q: Stable Diffusionは具体的に何に使えますか?
A: 主な用途として以下が挙げられます:
- 広告やマーケティング素材の作成
- キャラクターデザインや背景イラストの生成
- プロダクトデザインのコンセプト作成
- ロゴやブランディング要素の制作
- アートワークや創作活動の補助ツール
Q: 専門的なスキルがなくても使えますか?
A: はい、基本的な操作は直感的で、テキストプロンプトを入力するだけで画像を生成できます。ただし、より高度な表現を行うには、プロンプトエンジニアリングのスキルを磨く必要があります。
Q: 商用利用は可能ですか?
A: 基本的に商用利用可能ですが、使用するモデルやデータセットによって制限が異なる場合があります。必ず利用規約を確認し、必要に応じて権利者の許諾を得ることが重要です。
Q: 生成された画像の著作権はどうなりますか?
A: 法的な解釈は国や状況によって異なりますが、一般的にはAIが生成した画像の著作権は人間に帰属するとされています。ただし、入力したプロンプトや参照元の著作権には十分注意が必要です。
Q: Stable Diffusionの導入にはどのくらいのコストがかかりますか?
A: オープンソースのため、基本的に無料で利用できます。ただし、高性能なGPUを搭載したPCやクラウドサービスの利用には一定のコストがかかる場合があります。また、商用利用の場合は有料プランを選択する必要があるサービスもあります。
Stable Diffusionの未来展望
- マルチモーダル化: テキストだけでなく、音声や動画など複数のモダリティを組み合わせた生成が可能になると予想されています。
- リアルタイム処理: エッジAIの発展により、スマートフォンなどでもリアルタイムに高品質な画像生成が行えるようになるでしょう。
- カスタマイズ性の向上: 個人や企業のニーズに合わせて、より細かくモデルをカスタマイズできるようになると考えられています。
- 創造性支援ツールとしての進化: 人間のクリエイティブプロセスを補完し、新たな表現の可能性を広げるツールとして発展していくでしょう。
- 倫理的ガイドラインの整備: AIが生成したコンテンツの取り扱いに関する法的・倫理的なフレームワークが確立されていくと予想されます。
Stable Diffusionは、クリエイティブ産業に革命をもたらす可能性を秘めた技術です。その進化を注視しつつ、適切に活用していくことが、今後のビジネスや創作活動において重要になってくるでしょう。

Stable Diffusion aiの画像生成における日本語対応とその高品質

Stable Diffusionの日本語対応モデルにより、高品質な日本語画像生成が可能になりました。特に注目すべきは、Japanese Stable Diffusion XLとrinnaが開発した日本語特化モデルです。
これらのモデルは、約1億枚の日本語キャプション付き画像データを用いて学習されており、日本語の微妙なニュアンスや文化的背景を反映した画像生成が可能です。従来の英語モデルと比較して、より自然で違和感のない日本語テキストや日本的な要素を含む画像を生成できます。
画像生成のプロセスは非常にシンプルで、ユーザーは日本語のプロンプトを入力するだけで済みます。プロンプトの品質が出力画像の質に大きく影響するため、具体的で詳細な説明を心がけることが重要です。また、ネガティブプロンプトを活用することで、不要な要素を排除し、より意図に沿った画像を生成できます。
画質の調整には、サンプリング回数やCFGスケールなどのパラメータが用意されています。サンプリング回数を増やすと細部の精度が向上しますが、生成時間も長くなります。CFGスケールは入力プロンプトの影響度を調整し、高い値ほどプロンプトに忠実な画像が生成されます。
以下は、日本語Stable Diffusionモデルの特徴をまとめた表です:
| 特徴 | 詳細 |
|---|---|
| 学習データ | 約1億枚の日本語キャプション付き画像 |
| 言語対応 | 日本語プロンプトに直接対応 |
| 文化理解 | 日本の文化や伝統を反映した画像生成が可能 |
| テキスト生成 | 自然な日本語テキストを画像内に生成可能 |
| 商用利用 | 多くのモデルで商用利用が可能(要確認) |
これらの日本語対応モデルにより、クリエイティブ業界やマーケティング分野での活用が期待されています。アイデア出しやコンセプト可視化、プロモーション素材の作成など、幅広い用途で高品質な日本語画像生成が可能となりました。今後さらなるモデルの改良や新しい機能の追加により、日本語Stable Diffusionの可能性はさらに広がっていくでしょう。
Stable Diffusion aiと他の画像生成AIの比較・選び方・活用法
Stable Diffusion AIと他の主要な画像生成AIを比較し、選び方や活用法について解説します。

主要画像生成AIの比較
Stable DiffusionとDALL-E 2、Midjourneyの3つを比較すると、以下のような特徴があります:
| 特徴 | Stable Diffusion | DALL-E 2 | Midjourney |
|---|---|---|---|
| オープンソース | ○ | × | × |
| 無料利用 | ○ | 限定的 | × |
| カスタマイズ性 | 高 | 中 | 低 |
| 画質 | 良好 | 優秀 | 優秀 |
| 使いやすさ | やや難 | 簡単 | 中程度 |
選び方のポイント
- 予算: 無料で使いたい場合はStable Diffusionが最適
- カスタマイズ: 細かい調整をしたい場合もStable Diffusionがおすすめ
- 簡単さ: 手軽に使いたい場合はDALL-E 2が良い
- 画質重視: MidjourneyやDALL-E 2が高品質な画像を生成
活用事例と使用感
Stable Diffusionの主な活用事例:
- イラスト制作
- 写真編集・加工
- コンセプトアート作成
- 3DCGのテクスチャ生成
ユーザーの声を分析すると、以下のような傾向が見られます:
- 自由度が高く、独自のモデルを作れる点を評価
- 初心者には難しいという意見も
- 無料で高品質な画像が作れることに満足
- プロンプトの工夫次第で驚くような結果が得られる
効果的な活用のコツ
- プロンプトエンジニアリングを学ぶ
- 複数のモデルを試す
- パラメータ調整を積極的に行う
- コミュニティに参加して情報交換する
Stable Diffusionは柔軟性が高く、様々な用途に応用できるAIです。他のサービスと比較しながら、自分のニーズに合った活用法を見つけることが重要です。





